Bug #12399
closed
WireGuard v0.1.5 - Tunnel Will Never Handshake Again After WAN Reset
0%
Description
Hi Christian,
Really appreciate your work on the Wireguard package for pfSense :)
Sadly, there seems to be a show-stopping bug for me in the package. If my WAN connection drops due to an intentional modem reboot or other ISP issue, and is subsequently restored, my configured WireGuard tunnel in pfSense ceases to handshake after the WAN comes back even if I restart WireGuard services and/or restart pfSense completely. The only way I can get it to handshake again is by removing the configured Peer, completely removing the assigned interface from the Tunnel, deleting the tunnel, then recreating everything and re-associating all my firewall rules with the newly re-created interface. As you an can imagine this a quite a painful process.
I have tried simply disabling/re-enabling the assigned tunnel interface with an without the WireGuard services running but that does not make any different; the tunnel has to be completely removed and re-created for handshaking to occur. This issue is easily reproduceable by restarting my ISP modem. Below are the pfSense system logs during the modem reboot (WAN drop and re-establishment) along with the ifconfig output of my tun_wg0 interface, not sure if they are helpful:
Sep 23 09:24:58 rc.gateway_alarm 29027 >>> Gateway alarm: WANGW (Addr:192.168.7.1 Alarm:0 RTT:.476ms RTTsd:.426ms Loss:5%)
Sep 23 09:24:58 check_reload_status 375 updating dyndns WANGW
Sep 23 09:24:58 check_reload_status 375 Restarting ipsec tunnels
Sep 23 09:24:58 check_reload_status 375 Restarting OpenVPN tunnels/interfaces
Sep 23 09:24:58 check_reload_status 375 Reloading filter
Sep 23 09:25:00 xinetd 37636 Starting reconfiguration
Sep 23 09:25:00 xinetd 37636 Swapping defaults
Sep 23 09:25:00 xinetd 37636 readjusting service 6969-udp
Sep 23 09:25:00 xinetd 37636 Reconfigured: new=0 old=1 dropped=0 (services)
tun_wg0: flags=80c1<UP,RUNNING,NOARP,MULTICAST> metric 0 mtu 1420
description: WireGuardVPN
options=80000<LINKSTATE>
inet 10.7.0.2 netmask 0xffffffff
groups: wg WireGuard
nd6 options=101<PERFORMNUD,NO_DAD>
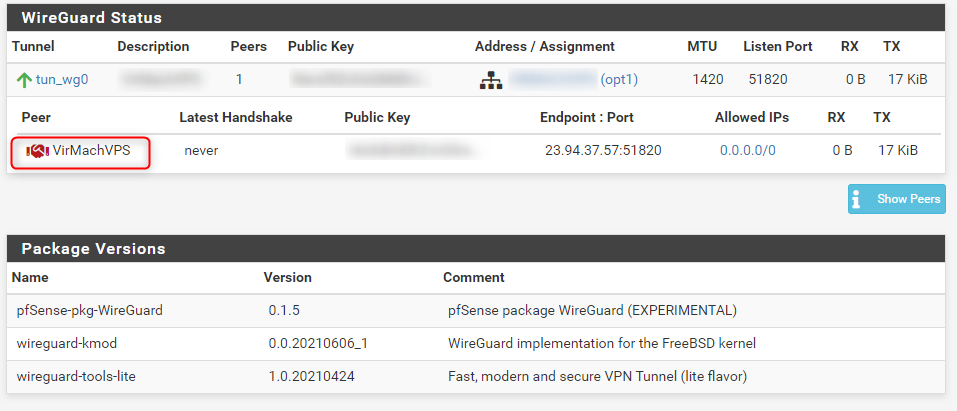
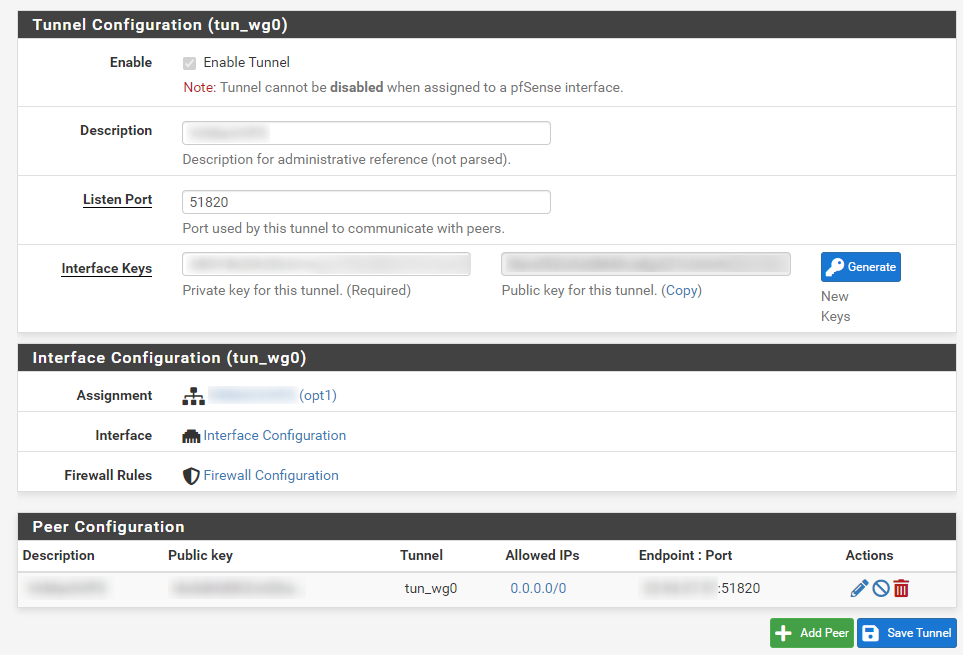
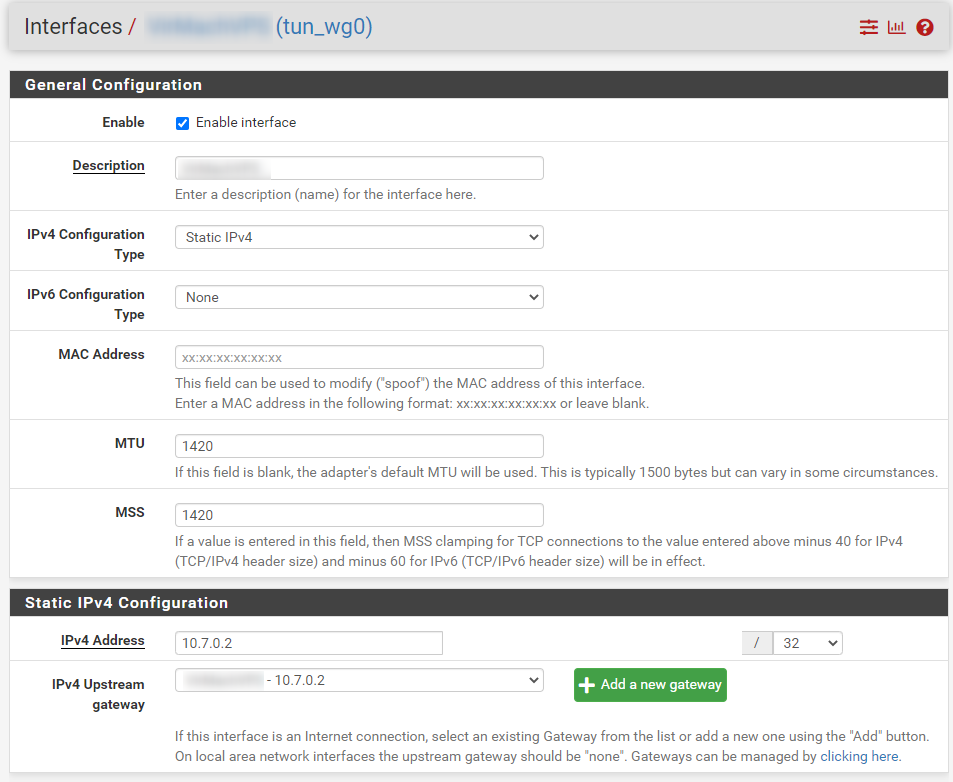
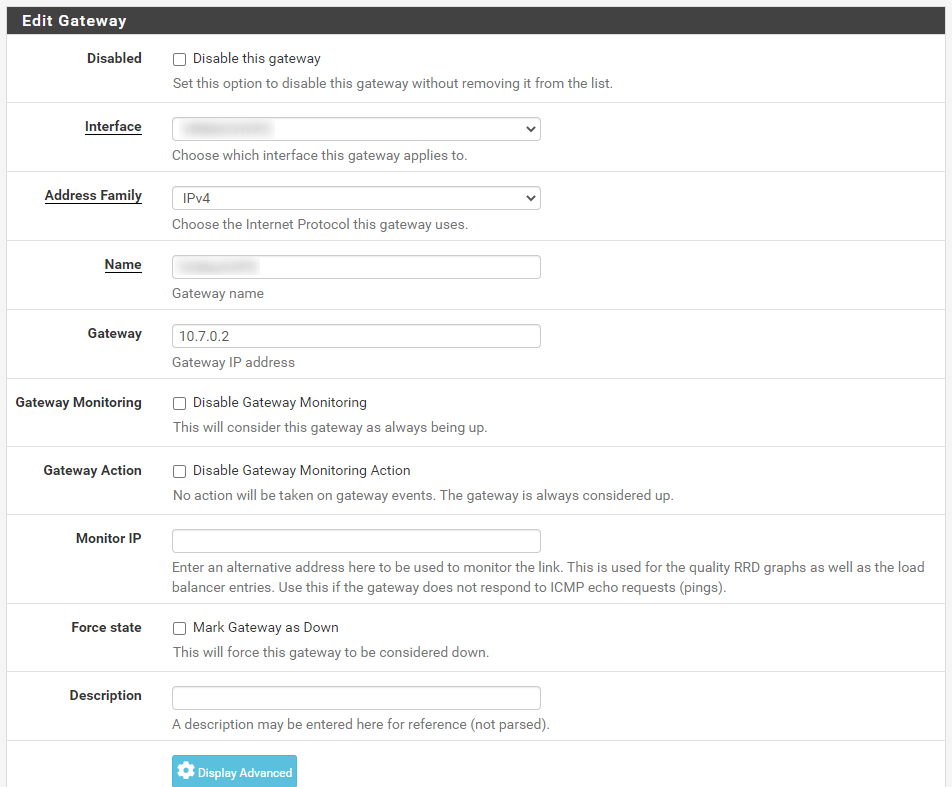
I do not have any other WireGuard or OpenVPN tunnels besides the one and am not using any sort of gateway groups for failover; just a very simple configuration. The 'server' peer I am connecting to from my local pfSense install is a VPS running WireGuard v1.0.20200513 and I am using a Pre-Shared key for 'client' peers including pfSense. I am using a keep-alive value of 30 seconds for the pfSense peer. Please let me know if I can supply any additional information to assist in troubleshooting. Screenshots attached showing the WireGuard in the state of disconnect after a WAN reset.
Files
| 2021-09-23_10h16_55.png (52.9 KB) 2021-09-23_10h16_55.png | Failed handshake status | ||
| 2021-09-23_10h18_03.png (69.2 KB) 2021-09-23_10h18_03.png | Tunnel config | ||
| 2021-09-23_10h20_37.png (78.1 KB) 2021-09-23_10h20_37.png | Assigned Interface config | ||
| 2021-09-23_10h21_32.png (63.5 KB) 2021-09-23_10h21_32.png | Assigned interface gateway config | ||
| 2021-09-23_10h19_09.png (88.2 KB) 2021-09-23_10h19_09.png | Peer config |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 Updated by Christian McDonald almost 5 years ago
Updated by Christian McDonald almost 5 years ago
Thanks for the tag, I will investigate this and circle back.
 Updated by Ryan Roosa almost 5 years ago
Updated by Ryan Roosa almost 5 years ago
Christian McDonald wrote in #note-1:
Thanks for the tag, I will investigate this and circle back.
Awesome! Greatly appreciate it :)
Updated by Ryan Roosa almost 5 years ago
In rebooting my ISP modem many times and tracking the behavior of pfSense and WireGuard, I observed that when the modem starts to come up and my LAN can reach the Internet again briefly, the WAN interface is reloaded by pfSense and WireGuard is able to reach the remote peer again completing one handshake successfully. However, as part of the ISP modem startup sequence (internal healthchecks, loading ISP routes, etc.) it appears the Internet becomes briefly inaccessible again for 30-60 seconds before this connectivity returns completely. It is during this second window of Internet inaccessibility after the intial modem restart that WireGuard reaches its customary 2 minute handshake interval and tries to handshake with the remote peer for a second time (after being able to reach it once already). This second handshake never takes place due to Internet connectivity temporarily being disrupted. Even when the Internet is fully reachable again by all LAN devices, no subsequent handshake attempts ever occur at this stage.
So, to summarize, if Internet connectivity to the remote peer is disrupted in the window of time between WireGuard's first and second handshake attempts after a pfSense WAN reload (due to restart of ISP modem connected to WAN), the configured tunnel in pfSense will never handshake to the assigned peer again on its own. Restarting WireGuard services or pfSense at this point yield no improvement. I cannot say with certainty at this point without further testing, but it would seem logical to me that this scenario may in fact reveal itself during other periods of WAN link instability where consecutive handshake attempts occurring at the ~2 minute interval are unsuccessful due to temporal WAN instability due to myriad reasons. Given these findings, if focus could be directed at handshake workflow and logic surrounding handshake retry attempts after a failed attempt I believe an ultimate solution can be found.
In the meantime, a workaround I found to get the tunnel handshaking with the remote peer again after this scenario occurs is to modify the tunnel listening port arbitrarily (i.e. changing it form '51820' to '51821'); saving/applying this change results in successful handshakes again. In the error scenario with my ISP modem, since WireGuard was observed to handshake once successfully after pfSense resets the WAN interface, another work around may be to re-execute the actions pfSense takes when the WAN is reloaded if handshaking attempts are observed to have ceased after a period of WAN instability. Taking that line of thought a step further, I suppose it would be possible to automate either workaround (tunnel port change or WAN reload actions) with a combo of shell scripting and the pfSense PHP Shell playback functionality but I have not gone down this road yet myself and would hope that the root cause could be resolved without resorting to band-aids like these :)
FWIW as a data point, I see that a Reddit user who replied to my OP in r/PFSENSE (https://www.reddit.com/r/PFSENSE/comments/ptx06g/wireguard_v015_tunnel_will_never_handshake_again/) indicated that they experienced similar behavior in v0.1.5 and that a downgrade to the previous release did not exhibit the issue.
Thanks again!
Updated by Christian McDonald almost 5 years ago
Just tested this on my 2100. I will test more next week.
I have a WireGuard tunnel to Mullvad.
- Started a persistent ping on LAN client
- Unplugged WAN, pings stop as expected.
- Plug in WAN, it takes a hot minute but eventually the first handshake is performed.
- As soon as I see the first handshake, I unplugged the WAN again.
- Now at this point we are in the period of time between the first and the second handshake.
- I reattach WAN...again it takes a hot minute, but eventually connectivity is restored and works correctly.
Hmm. I will test some other scenarios next week.
Updated by Christian McDonald almost 5 years ago
Ryan, out of curiosity, are you using DHCP are static addressing on your WAN?
Updated by Ryan Roosa almost 5 years ago
Christian McDonald wrote in #note-5:
Ryan, out of curiosity, are you using DHCP are static addressing on your WAN?
My WAN uses static addressing.
Updated by Christian McDonald almost 5 years ago
Interesting... I can replicate this if my WAN is using DHCP, but as soon as I switch to a static address I can unplug and replug WAN all day at any cadence and it works fine.
What is your system default gateway set to? If it is set to Automatic, set it to your WAN explicitly.
Updated by Ryan Roosa almost 5 years ago
Christian McDonald wrote in #note-7:
Interesting... I can replicate this if my WAN is using DHCP, but as soon as I switch to a static address I can unplug and replug WAN all day at any cadence and it works fine.
What is your system default gateway set to? If it is set to Automatic, set it to your WAN explicitly.
Thank you for the feedback and suggestions! I am not home at the moment but will double check when I get back that my WAN has not reverted to DHCP for some reason. Will also check my gateway setting but believe I have WAN explicitly set as much default gateway already.
Updated by Christian McDonald almost 5 years ago
Thanks.
We might need to hook the gateway alarm and trigger WireGuard service to be restarted when gateway status changes...like we already do for ipsec, openvpn, dyndns, etc.
Updated by Ryan Roosa almost 5 years ago
Christian McDonald wrote in #note-9:
Thanks.
We might need to hook the gateway alarm and trigger WireGuard service to be restarted when gateway status changes...like we already do for ipsec, openvpn, dyndns, etc.
I confirmed my WAN is static and set as default gateway. Would hooking the gateway alarm to restart WireGuard restart it in a different way than what is already available in the GUI? I restarted the services manually in the GUI a few times and it did not seem to help. The only thing that helped seemed to be changing the tunnel port number.
 Updated by Samuel Hanna almost 5 years ago
Updated by Samuel Hanna almost 5 years ago
The problem still persist on wireguard 0.1.5_1.
even after changing the keys and ports nothing seems to help.
wish that you can fix this issue ASAP.
my wan connection is PPPOE with 1492 mtu value, tried to lower the mtu of WG interface lower than 1420, also didn't help.
Updated by Ryan Roosa almost 5 years ago
Samuel Hanna wrote in #note-11:
The problem still persist on wireguard 0.1.5_1.
even after changing the keys and ports nothing seems to help.
wish that you can fix this issue ASAP.
my wan connection is PPPOE with 1492 mtu value, tried to lower the mtu of WG interface lower than 1420, also didn't help.
Just an update from my side...
My 'after WAN reset' wording in the bug description may be somewhat of a misnomer based on my further testing. After many hours of playing with this (as well as having it break organically again at least twice) I've been able to consistently reproduce the issue by:
- Taking my WAN connection offline without disrupting its Ethernet connection to pfSense (logging into my modem interface and disconnecting from the upstream ISP without disconnecting the Ethernet connection).
- Waiting the equivalent of two handshake intervals (2-4 minutes depending on when the last successful handshake occurred).
- Taking my WAN connection back online.
After step 3, tunnel handshaking suspends indefinitely and restarting Wireguard services or the WAN interface in pfSense does nothing to correct this error state even though the rest of my LAN is back online without issue.
Since I do not see any updates on a fix for this bug as of yet, I created a shell script equivalent of the workaround I discovered (changing the tunnel port arbitrarily then later reverting back to the port originally configured for consistency within the package). I really dislike using bandaids such as this but I'm not sure when this bug might be fixed and I need to insure against unknown future WAN instability killing my Wireguard tunnels.
The following is my shell script which is called every 10 minutes (*/10 * * * *) via the 'Cron' package in pfSense:#!/bin/sh
[ $(( $(date +s) - $(wg show tun_wg0 latest-handshakes | awk '{print $2}') )) -gt 300 ] &x%x \
wg set tun_wg0 listen-port 51$(tr -cd 0-9 </dev/urandom | head -c 3) && sleep 300 && \
wg syncconf tun_wg0 /usr/local/etc/wireguard/tun_wg0.conf && \
echo "$(date) - Had to jiggle the tunnel port to fix handshaking!" >> /var/log/wg_bandaid.log
exit 0
(Updated script; do not use the one above. See: https://redmine.pfsense.org/issues/12399#note-16 .)
Breaking it down line by line:
- The script starts by checking if it has been longer than 5 minutes since the last handshake. If not, then the script exits without taking any action.
- If the last handshake took place longer than 5 minutes ago, the tunnel listen port is changed arbitrarily ('51NNN'). The script then waits 5 minutes to allow the tunnel to handshake twice successfully again before proceeding.
- Once the waiting interval has passed, a configuration sync is executed which updates the listen port back to what it was prior to the script changing it (it does this by comparing the running configuration to the configuration file saved at OS level by the package).
- A log of the script's intervention is written to '/var/log/wg_bandaid.log' for posterity.
- Finally, the script exits with a success code (0).
Technically the script body is just a long 'one-liner' which is broken up into multiple lines for readability and easier explanation. Of note, I found that the 'sleep' command must be at least 4-5 minutes (I settled on 5 minutes = 300 seconds) by trial and error testing. If I reverted the port any sooner, the tunnel would stop handshaking again. Maybe this is a clue to the source of the bug? Not sure, but thought it was worth sharing for those wondering why this specific interval of wait time was chosen (as an aside, sleeps are not really a hallmark of great programming in general but since this is a bandaid, I've decided to use it regardless).
One other interesting thing I found is that the tunnel configuration file stored at OS level ('/usr/local/etc/wireguard/tun_wg0.conf') is always missing the tunnel endpoint IP information. This info is obviously stored elsewhere in the pfSense package configuration since it shows up in the web interface so I'm not sure if its omission in the OS level configuration file is intentional or not but this is why I chose to use 'syncconf' as opposed to 'setconf' when having the script revert the tunnel port after arbitrarily changing it (and, as the 'wg' man page indicates, 'syncconf' is more efficient anyways with the added benefit of not further disrupting the active peer connection).
I provide no warranty with this script and it assumes your only tunnel is 'tun_wg0'. More complex setups may necessitate tweaks and/or additional logic. Caveat emptor.
Updated by Christian McDonald almost 5 years ago
Thank you for the detailed report here. This is immensely helpful. I will continue to poke at this next week and report back. It would be interesting to see if this behavior also happens on vanilla FreeBSD, I will test this as well. If this happens to be reproducible there as well, then that's a good indicator of an upstream issue.
And yes, the endpoint is not stored in the configuration file because of reasons why how WireGuard handles name resolution. WireGuard tools only performs resolution once, at tunnel creation. So it is left up to additional tooling to nudge WireGuard to re-resolve these endpoints. The rationale here, is that endpoint addresses at the level of the kernel code is fixed length, 32-128bit, so leaving the DNS resolution out of the kernel and leaving it to userspace tooling eliminates parsing vuls, etc.
Updated by Samuel Hanna almost 5 years ago
Ryan Roosa wrote in #note-12:
Samuel Hanna wrote in #note-11:
The problem still persist on wireguard 0.1.5_1.
even after changing the keys and ports nothing seems to help.
wish that you can fix this issue ASAP.
my wan connection is PPPOE with 1492 mtu value, tried to lower the mtu of WG interface lower than 1420, also didn't help.Just an update from my side...
My 'after WAN reset' wording in the bug description may be somewhat of a misnomer based on my further testing. After many hours of playing with this (as well as having it break organically again at least twice) I've been able to consistently reproduce the issue by:
- Taking my WAN connection offline without disrupting its Ethernet connection to pfSense (logging into my modem interface and disconnecting from the upstream ISP without disconnecting the Ethernet connection).
- Waiting the equivalent of two handshake intervals (2-4 minutes depending on when the last successful handshake occurred).
- Taking my WAN connection back online.
After step 3, tunnel handshaking suspends indefinitely and restarting Wireguard services or the WAN interface in pfSense does nothing to correct this error state even though the rest of my LAN is back online without issue.
Since I do not see any updates on a fix for this bug as of yet, I created a shell script equivalent of the workaround I discovered (changing the tunnel port arbitrarily then later reverting back to the port originally configured for consistency within the package). I really dislike using bandaids such as this but I'm not sure when this bug might be fixed and I need to insure against unknown future WAN instability killing my Wireguard tunnels.
The following is my shell script which is called every 10 minutes (*/10 * * * *) via the 'Cron' package in pfSense:
#!/bin/sh
[ $(( $(date +s) - $(wg show tun_wg0 latest-handshakes | awk '{print $2}') )) -gt 300 ] &x%x \
wg set tun_wg0 listen-port 51$(tr -cd 0-9 </dev/urandom | head -c 3) && sleep 300 && \
wg syncconf tun_wg0 /usr/local/etc/wireguard/tun_wg0.conf && \
echo "$(date) - Had to jiggle the tunnel port to fix handshaking!" >> /var/log/wg_bandaid.log
exit 0Breaking it down line by line:
- The script starts by checking if it has been longer than 5 minutes since the last handshake. If not, then the script exits without taking any action.
- If the last handshake took place longer than 5 minutes ago, the tunnel listen port is changed arbitrarily ('51NNN'). The script then waits 5 minutes to allow the tunnel to handshake twice successfully again before proceeding.
- Once the waiting interval has passed, a configuration sync is executed which updates the listen port back to what it was prior to the script changing it (it does this by comparing the running configuration to the configuration file saved at OS level by the package).
- A log of the script's intervention is written to '/var/log/wg_bandaid.log' for posterity.
- Finally, the script exits with a success code (0).
Technically the script body is just a long 'one-liner' which is broken up into multiple lines for readability and easier explanation. Of note, I found that the 'sleep' command must be at least 4-5 minutes (I settled on 5 minutes = 300 seconds) by trial and error testing. If I reverted the port any sooner, the tunnel would stop handshaking again. Maybe this is a clue to the source of the bug? Not sure, but thought it was worth sharing for those wondering why this specific interval of wait time was chosen (as an aside, sleeps are not really a hallmark of great programming in general but since this is a bandaid, I've decided to use it regardless).
One other interesting thing I found is that the tunnel configuration file stored at OS level ('/usr/local/etc/wireguard/tun_wg0.conf') is always missing the tunnel endpoint IP information. This info is obviously stored elsewhere in the pfSense package configuration since it shows up in the web interface so I'm not sure if its omission in the OS level configuration file is intentional or not but this is why I chose to use 'syncconf' as opposed to 'setconf' when having the script revert the tunnel port after arbitrarily changing it (and, as the 'wg' man page indicates, 'syncconf' is more efficient anyways with the added benefit of not further disrupting the active peer connection).
I provide no warranty with this script and it assumes your only tunnel is 'tun_wg0'. More complex setups may necessitate tweaks and/or additional logic. Caveat emptor.
thanks for your help. but i have detected that the handshake is getting interrupted by my ISP. as they started to block whole wireguard protocol all over the country. :D
Updated by Ryan Roosa almost 5 years ago
Christian McDonald wrote in #note-13:
Thank you for the detailed report here. This is immensely helpful. I will continue to poke at this next week and report back. It would be interesting to see if this behavior also happens on vanilla FreeBSD, I will test this as well. If this happens to be reproducible there as well, then that's a good indicator of an upstream issue.
And yes, the endpoint is not stored in the configuration file because of reasons why how WireGuard handles name resolution. WireGuard tools only performs resolution once, at tunnel creation. So it is left up to additional tooling to nudge WireGuard to re-resolve these endpoints. The rationale here, is that endpoint addresses at the level of the kernel code is fixed length, 32-128bit, so leaving the DNS resolution out of the kernel and leaving it to userspace tooling eliminates parsing vuls, etc.
No problem! Appreciate your continued attention on this one.
Thanks for highlighting the additional information surrounding DNS resolution which explains why the endpoint is not stored in the OS level configuration file. Your explanation leads me to some additional questions:
- Does the WireGuard package for pfSense (or WG in general) still try resolution even if the tunnel is configured using an IP address for the endpoint?
- In the case that the tunnel endpoint is specified as an IP address should the best practice be to set "Endpoint Hostname Resolve Interval" to "0" to disable this periodic resolution check in order to prevent some issue that might be encountered when attempting to resolve a host entered as an IP?
Updated by Ryan Roosa almost 5 years ago
FWIW, just wanted to share updates I've made to my bandaid script. I found that 'head -c' usage on '/dev/urandom' likes to hang and not close the device properly when the script runs in background as a cron job. So I switched that part to use 'jot' for random port number generation and wrapped the core one-liner with some basic pidfile logic to keep the script from stacking executions. The latter allows calling the script more frequently (I have it running every 5 minutes now). Finally, added very rudimentary log cleanup to keep it from growing too large in case something goes nuts with it.
#!/bin/sh
LOGFILE=/var/log/wg_bandaid.log
PIDFILE=/var/run/wg_bandaid.pid
TUNNAME=tun_wg0
TUNCONF=/usr/local/etc/wireguard/$TUNNAME.conf
STRPCNF=/tmp/$TUNNAME.conf
OPNSNSE=$(which wg-quick)
# Preliminary logic to ensure this only runs one instance at a time
if [ -f $PIDFILE ]
then
PID=$(cat $PIDFILE)
ps -p $PID > /dev/null 2>&1
if [ $? -eq 0 ]
then
echo "$(date) - Process already running. Exiting." >> $LOGFILE
exit 1
else
echo $$ > $PIDFILE
if [ $? -ne 0 ]
then
echo "$(date) - Could not create PID file. Exiting." >> $LOGFILE
exit 1
fi
fi
else
echo $$ > $PIDFILE
if [ $? -ne 0 ]
then
echo "$(date) - Could not create PID file. Exiting." >> $LOGFILE
exit 1
fi
fi
# Check if running OPNSense and cleanup tunnel config file if so
[ ! -z $OPNSNSE ] && wg-quick strip $TUNCONF > $STRPCNF && TUNCONF=$STRPCNF
# Main command
[ $(( $(date +%s) - $(wg show $TUNNAME latest-handshakes | awk '{print $2}') )) -gt 300 ] && \
wg set $TUNNAME listen-port 51$(jot -r 1 100 999) && sleep 300 && \
wg syncconf $TUNNAME $TUNCONF && \
echo "$(date) - Had to jiggle $TUNNAME listen-port to fix handshaking!" >> $LOGFILE
# Cleanup after ourselves
[ -f $STRPCNF ] && rm $STRPCNF
rm $PIDFILE
# Keep log from getting too large
if [ -f $LOGFILE ]
then
echo "$(tail -1000 $LOGFILE)" > $LOGFILE
fi
exit 0
(10-25-21 Update: given comparison testing under OPNSense, I have added a few lines to make this script compatible there as well given the use of wg-quick)
Updated by Ryan Roosa almost 5 years ago
Just a quick update to let you know I've tested for this issue on the latest community release of OPNsense (21.7.3_3) since I was able to test with the same version of the wireguard kernel module (wireguard-kmod 0.0.20210606_1) which is utilized by pfSense. I have confirmed the issue exists in OPNsense as well so your thoughts regarding an upstream issue in wireguard-freebsd itself appear to be correct. To that end I've reached out to the official wireguard mailing list to share details of the issue and request their review of it. However, I'm a nobody to them so if Netgate or Christian specifically has any contacts over on the FreeBSD wireguard-kmod development team the confirmation of this issue and its detail might mean more coming from you :)
Thank you,
-Ryan
Updated by Christian McDonald over 4 years ago
Ryan Roosa wrote in #note-17:
Just a quick update to let you know I've tested for this issue on the latest community release of OPNsense (21.7.3_3) since I was able to test with the same version of the wireguard kernel module (wireguard-kmod 0.0.20210606_1) which is utilized by pfSense. I have confirmed the issue exists in OPNsense as well so your thoughts regarding an upstream issue in wireguard-freebsd itself appear to be correct. To that end I've reached out to the official wireguard mailing list to share details of the issue and request their review of it. However, I'm a nobody to them so if Netgate or Christian specifically has any contacts over on the FreeBSD wireguard-kmod development team the confirmation of this issue and its detail might mean more coming from you :)
Thank you,
-Ryan
Ryan,
Thanks for the continued investigation here. I'm tracking the kernel module development closely. Preliminary reports are looking good that this issue has been resolved upstream. We will of course merge in the patch and release an update as soon as it is available.
Updated by Ryan Roosa over 4 years ago
Ryan,
Thanks for the continued investigation here. I'm tracking the kernel module development closely. Preliminary reports are looking good that this issue has been resolved upstream. We will of course merge in the patch and release an update as soon as it is available.
No problem, thanks for your reply.
Yes, it looks like there is a patch which will be part of the next snapshot: https://w-g.pw/l/yQTw
Very happy to see the development team reviewed my report and issued a patch so quickly.
Fingers crossed this will fix the issue :)
Updated by Christian McDonald over 4 years ago
- Status changed from New to Confirmed
Updated by Christian McDonald over 4 years ago
- Target version changed from Future to 2.6.0
- Plus Target Version set to 22.01
- Affected Version deleted (
2.5.2) - Affected Architecture All added
- Affected Architecture deleted (
amd64)
Updated by Christian McDonald over 4 years ago
- Status changed from Confirmed to Feedback
We have pulled in the upstream patches and bumped our version numbers. You should find a new package version available tomorrow on the devel snapshots.
Updated by Christian McDonald over 4 years ago
Look for Package Version 0.1.5_2, which will also upgrade net/wireguard-kmod to 0.0.20210606_2. Both are available on 22.01 and 2.6.0 devel snapshots.
From what I can tell, recovering from WAN issues does feel better, though I'm really eager to hear from individuals who have been able to consistently hit this problem.
Updated by Ryan Roosa over 4 years ago
Christian McDonald wrote in #note-24:
Look for Package Version 0.1.5_2, which will also upgrade net/wireguard-kmod to 0.0.20210606_2. Both are available on 22.01 and 2.6.0 devel snapshots.
From what I can tell, recovering from WAN issues does feel better, though I'm really eager to hear from individuals who have been able to consistently hit this problem.
Okay, finally got back to flashing my dev hardware with 2.6.0 snapshot and loading up 0.1.5_2 WG package. In my testing of removing WAN connectivity various intervals of up to 10 minutes at a time it appears the issue is resolved as handshaking has resumed successfully each and every time without fail.
Thank you for keeping on top of this one, really appreciate it! Also, thanks for the YT shoutout, you're too kind. Just trying to do my part to make sure the WG implementation on pfSense (and FreeBSD distro in general) can run as smoothly as possible :)
Updated by Christian McDonald over 4 years ago
- Status changed from Feedback to Resolved
Excellent! Thanks for the continued feedback!
:)
 Updated by Nunya Business over 3 years ago
Updated by Nunya Business over 3 years ago
This problem has returned with the current version of the Wireguard package, 1.1.6_2.
Identical symptoms: make any changes to the tunnel, any at all, even just rebooting or restarting pfSense, and your WireGuard tunnel is borked. The only way to get connected again is to blow away all of it, reinstall your tunnels, peers, and related configurations. Then don't touch it and pray nothing goes wrong. You can't switch peers anymore, as this borks the tunnel.
 Updated by Prime BDE over 3 years ago
Updated by Prime BDE over 3 years ago
Nunya Business wrote in #note-27:
This problem has returned with the current version of the Wireguard package, 1.1.6_2.
Identical symptoms: make any changes to the tunnel, any at all, even just rebooting or restarting pfSense, and your WireGuard tunnel is borked. The only way to get connected again is to blow away all of it, reinstall your tunnels, peers, and related configurations. Then don't touch it and pray nothing goes wrong. You can't switch peers anymore, as this borks the tunnel.
I have the same problem. During any WAN reset event, WG tunnels are not established after connectivity is restored. IPSec tunnels work just fine. The only way I can get the WG tunnels to come back up is by changing the listening port. On Pfsense+ 23.01 and WG package 0.1.6_5. WAN is using DHCP.
 Updated by Gianluca Semadeni over 3 years ago
Updated by Gianluca Semadeni over 3 years ago
Prime BDE wrote in #note-28:
Nunya Business wrote in #note-27:
This problem has returned with the current version of the Wireguard package, 1.1.6_2.
Identical symptoms: make any changes to the tunnel, any at all, even just rebooting or restarting pfSense, and your WireGuard tunnel is borked. The only way to get connected again is to blow away all of it, reinstall your tunnels, peers, and related configurations. Then don't touch it and pray nothing goes wrong. You can't switch peers anymore, as this borks the tunnel.
I have the same problem. During any WAN reset event, WG tunnels are not established after connectivity is restored. IPSec tunnels work just fine. The only way I can get the WG tunnels to come back up is by changing the listening port. On Pfsense+ 23.01 and WG package 0.1.6_5. WAN is using DHCP.
Same issue here, after a WAN disconnect (pfSense 23.01, WireGuard pkg 0.1.6_5, static WAN IP's on both site). I have a Site-to-Site VPN through WireGuard. The problem with the service is only on one site. The first site with 5 WireGuard tunnel and 10 peers works perfectly fine. The second site, with only one tunnel & peer, has the described problem with the service that don't come up.
I have seen, that one of my static routes, for a specific WireGuard Peer, is disabled (on the second site). The WireGuard Service can't be started at that moment.
A working workaround is to manually enable that static route. Then the WireGuard Service can be started normally. After the WireGuard Service is up and running, the normal DHCP Service will crash. That service can be restarted without any Problems.