Bug #3692
closed
apinger loss % gets stuck
0%
Description
I have noticed on multiple (5) independent pfSense installs/locations/ISPs (both active/passive and single-node, x86 and x64) running the pfSense 2.1.x series that the apinger packet loss percentage has a tendency to get "stuck" on a particular baseline value after a high-loss episode.
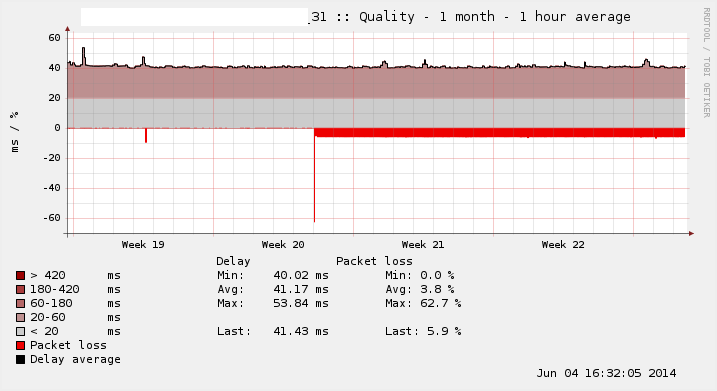
I have attached two RRD graphs from one router for illustration. As you can see in the attached monthly graph this problem seemingly gets triggered by a real episode of high packet loss but instead of recovering to a baseline of zero percent in this particular example the baseline stays at 6% forever and any actual packet loss is added to that 6%.
Restarting apinger solves the problem and resets the baseline to 0%.
The incorrect packet-loss percentage is reflected both in the RRD graphs as well as the Gateways dashboard widget.
Files
 Updated by
Updated by {kind=link}
{kind=link}
{kind=link}
{kind=link}
 Updated by Jason Ross about 12 years ago
Updated by Jason Ross about 12 years ago
I noticed this yesterday. For a period of time I had a bad episode of packetloss on a WAN gateway and even though the issue was resolved a long time ago it is still indicating there is a problem even more than 24 hours later:
Warning, Packetloss: 82%
 Updated by Anonymous about 12 years ago
Updated by Anonymous about 12 years ago
I'm having the same issue with 2.1.4.
I have to restart the entire pfsense box to correct it, just restarting the apinger service doesn't help.
Packet loss seems to get stuck at different values, I have no idea what's causing it but there isn't anywhere near that amount of packet loss on my line, which is confirmed after a restart when it drops to 0 again.
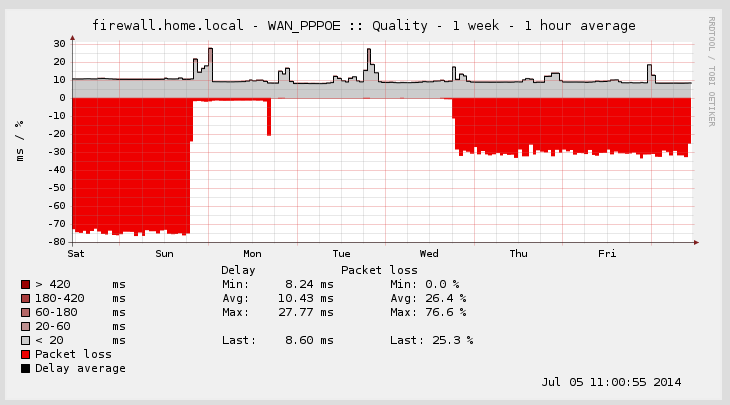
Attached is what my rrd history looks like.
 Updated by Denny Page about 12 years ago
Updated by Denny Page about 12 years ago
I just got bit by this again running 2.1.4. For me, it happens every few weeks. and is always associated with an elevated latency event.
Has anyone looked at this?
 Updated by Ralf Hauptmann about 12 years ago
Updated by Ralf Hauptmann about 12 years ago
i have the same problem on two pfsense machines.
Updated by Denny Page about 12 years ago
Just got bit with this again. Different symptoms this time... Gateway status (home page) showed 102% loss. RRD graphs showed nan. Restart of apinger service corrected the issue.
Updated by Denny Page almost 12 years ago
And again. Is there any diagnostic information that we can gather to help with this???
 Updated by Sam E almost 12 years ago
Updated by Sam E almost 12 years ago
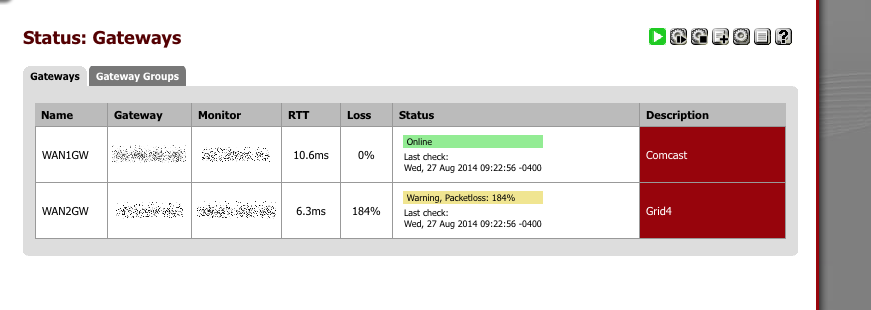
I have one location that consistently has this problem if you need us to help you test something. Since the packet loss percent never resets this makes failover 1000% non-functional because interface is eliminated as a failover candidate because of the fake packet loss level. This caused an outage for our client last week because failover didn't work when the other interface REALLY went down.
The 184% packet loss in the attached image accumulated over just 12 hours.
Updated by Sam E almost 12 years ago
Sorry. This was happening in 2.1.3 and after an upgrade to 2.1.4 it is still happening.
Updated by Denny Page almost 12 years ago
Since upgrading to 2.1.5, I've also had two instances of apinger getting stuck on elevated latency rather than loss. Two successive days. Interestingly, both occurrences began at exactly the same time of day. The first was cured by restarting the firewall (I did not try just restarting apinger) and the second by restarting apinger.
Apinger is such an important service and appears to be growing non-functional. Is there anything we can do?
 Updated by Doktor Notor almost 12 years ago
Updated by Doktor Notor almost 12 years ago
Denny Page wrote:
Apinger is such an important service and appears to be growing non-functional. Is there anything we can do?
Make it no-op. An excerpt from today:
Sep 2 06:46:25 php: rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use HEIPV6_TUNNELV6. Sep 2 06:46:24 php: rc.newipsecdns: IPSEC: One or more IPsec tunnel endpoints has changed its IP. Refreshing. Sep 2 06:46:17 check_reload_status: Reloading filter Sep 2 06:46:17 check_reload_status: Restarting OpenVPN tunnels/interfaces Sep 2 06:46:17 check_reload_status: Restarting ipsec tunnels Sep 2 06:46:17 check_reload_status: updating dyndns HEIPV6_TUNNELV6 Sep 2 06:46:07 apinger: alarm canceled: HEIPV6_TUNNELV6(2001:470:xx:xx::1) *** delay *** Sep 2 06:45:47 apinger: alarm canceled: WANGW(37.xx.xx.xx) *** delay *** Sep 2 06:45:14 apinger: ALARM: WANGW(37.xx.xx.xx) *** delay *** Sep 2 06:45:10 apinger: ALARM: HEIPV6_TUNNELV6(2001:470:xx:xx::1) *** delay ***
Sorry, all the IPs are static on both sides. None of the endpoints may have changed its IP
Summary
- generally broken, showing nonsensical >100% values for packet loss
- getting stuck randomly
- causing totally useless services restart
And noone from devs can reproduce? Gimme a break.
 Updated by Ermal Luçi almost 12 years ago
Updated by Ermal Luçi almost 12 years ago
Please update latest version of 2.2 of rebuilt apinger manually and retry.
Updated by Ermal Luçi almost 12 years ago
- Status changed from New to Feedback
Please try again with latest snapshots.
Updated by Ermal Luçi over 11 years ago
People have confirmed that the behaviour is improved.
Only the graph part needs improvement.
 Updated by Chris Buechler over 11 years ago
Updated by Chris Buechler over 11 years ago
- Status changed from Feedback to Resolved
seems this has been resolved. I haven't been able to replicate the circumstances here since Ermal's last round of fixes and the "please fix apinger" thread ended weeks ago with resolutions after Ermal's fixes, or the problem being a screwed up timecounter in a VM.
 Updated by Mario Giammarco over 11 years ago
Updated by Mario Giammarco over 11 years ago
I hate to say it but in a new pfsense 2.2 installation (with two wan load balancing and high availability) I have now 2190% packet loss on second wan (and usually more than 100% on first wan).
 Updated by Michael Kellogg over 11 years ago
Updated by Michael Kellogg over 11 years ago
this is back for me and I dont't know why this suddenly showed up and why restarting apinger no longer fixes this. also seeing ping times of 0.1 ms too