Bug #12926
closed
Changing LAGG type on CARP interfaces makes VIPs go to an "init" State
0%
Description
When changing a LAGG from any mode to another mode while it has child interfaces that are something like VLANs and CARP VIPs on them will cause CARP to go to an init status and never recover.
If you re-save the interface or reboot the firewall, they will go back to MASTER or BACKUP (depending on if it's primary or secondary). This can be worked around by failing over manually before making these changes and rebooting the firewall you're working on to avoid disruption, but this seems like a bug that should not present itself.
Bug was present in 2.6 of CE and 22.01 of pfSense Plus.
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related issues
 Updated by Viktor Gurov over 4 years ago
Updated by Viktor Gurov over 4 years ago
- Status changed from New to Feedback
- Affected Version set to 2.6.0
Unable to reproduce:
lagg0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
description: OPT2
options=6900bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,VLAN_HWFILTER,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6>
ether de:e1:87:63:8d:8a
inet6 fe80::dce1:87ff:fe63:8d8a%lagg0 prefixlen 64 scopeid 0xc
laggproto lacp lagghash l2,l3,l4
laggport: vtnet3 flags=0<>
groups: lagg
media: Ethernet autoselect
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
lagg0.11: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
description: VLAN11
options=680003<RXCSUM,TXCSUM,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6>
ether de:e1:87:63:8d:8a
inet6 fe80::dce1:87ff:fe63:8d8a%lagg0.11 prefixlen 64 scopeid 0xd
inet 10.22.22.100 netmask 0xffffff00 broadcast 10.22.22.255
inet 10.22.22.22 netmask 0xffffff00 broadcast 10.22.22.255 vhid 1
groups: vlan
carp: MASTER vhid 1 advbase 1 advskew 0
vlan: 11 vlanpcp: 0 parent interface: lagg0
media: Ethernet autoselect
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
after changing the LAGG mode from LACP to ROUNDROBIN:
lagg0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
description: OPT2
options=6900bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,VLAN_HWFILTER,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6>
ether de:e1:87:63:8d:8a
inet6 fe80::dce1:87ff:fe63:8d8a%lagg0 prefixlen 64 scopeid 0xc
laggproto roundrobin lagghash l2,l3,l4
laggport: vtnet3 flags=4<ACTIVE>
groups: lagg
media: Ethernet autoselect
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
lagg0.11: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
description: VLAN11
options=680003<RXCSUM,TXCSUM,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6>
ether de:e1:87:63:8d:8a
inet6 fe80::dce1:87ff:fe63:8d8a%lagg0.11 prefixlen 64 scopeid 0xd
inet 10.22.22.100 netmask 0xffffff00 broadcast 10.22.22.255
inet 10.22.22.22 netmask 0xffffff00 broadcast 10.22.22.255 vhid 1
groups: vlan
carp: MASTER vhid 1 advbase 1 advskew 0
vlan: 11 vlanpcp: 0 parent interface: lagg0
media: Ethernet autoselect
status: active
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
Please provide more details about this issue.
 Updated by Kris Phillips over 4 years ago
Updated by Kris Phillips over 4 years ago
Viktor Gurov wrote in #note-1:
Unable to reproduce:
[...]after changing the LAGG mode from LACP to ROUNDROBIN:
[...]Please provide more details about this issue.
Viktor,
When testing with a customer, they had several dozen VLAN interfaces (around 50). Likely this is needed to trigger this.
 Updated by Azamat Khakimyanov over 3 years ago
Updated by Azamat Khakimyanov over 3 years ago
- File first_error_after_changing_LAGG_type.png first_error_after_changing_LAGG_type.png added
- File after_pressing_Reset_CARP_Demotion_Status.png after_pressing_Reset_CARP_Demotion_Status.png added
- File after_about_10_minutes.png after_about_10_minutes.png added
- File gateway_timeout.png gateway_timeout.png added
- Status changed from Feedback to Confirmed
Tested on 22.01
I was able to reproduce this bug.
I've created HA cluster with LAGG interface on each node and 30 VLANs on these LAGG ports.
Changing LAGG type made HA cluster very unstable:
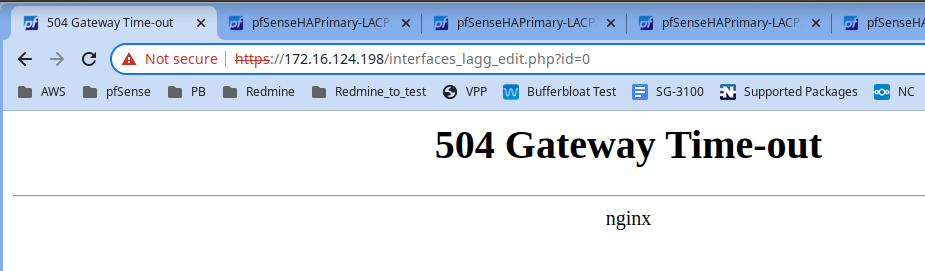
- after changing LAGG type 'Interface LAGG edit' page started to reload and finally I got '504 Gateway timeout'('gateway_timeout.png') but in /Status/Interfaces I saw that LAGG type were changed correctly and were changed immediately.
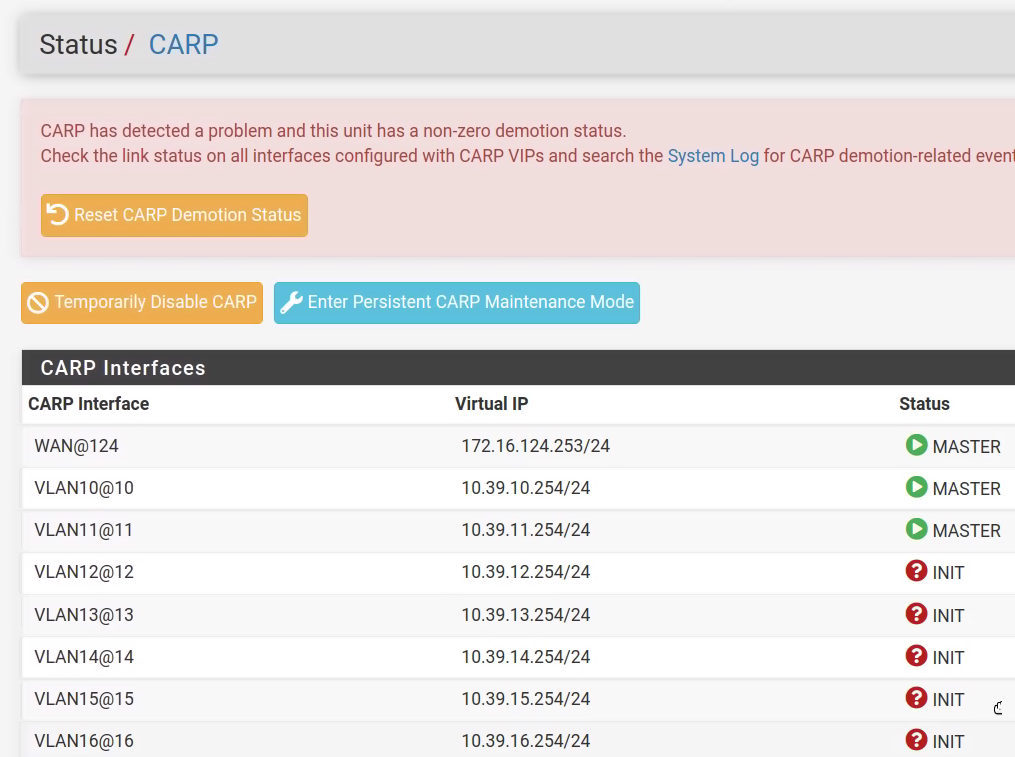
- I got 'CARP has detected a problem and this unit has a non-zero demotion status...' message and most of VLAN CARP VIPs were in INIT state (see attached 'first_error_after_changing_LAGG_type.png')
- after pressing 'Reset CARP Demotion Status' most of VLAN CARPs were in INIT state ('after_pressing_Reset_CARP_Demotion_Status.png')
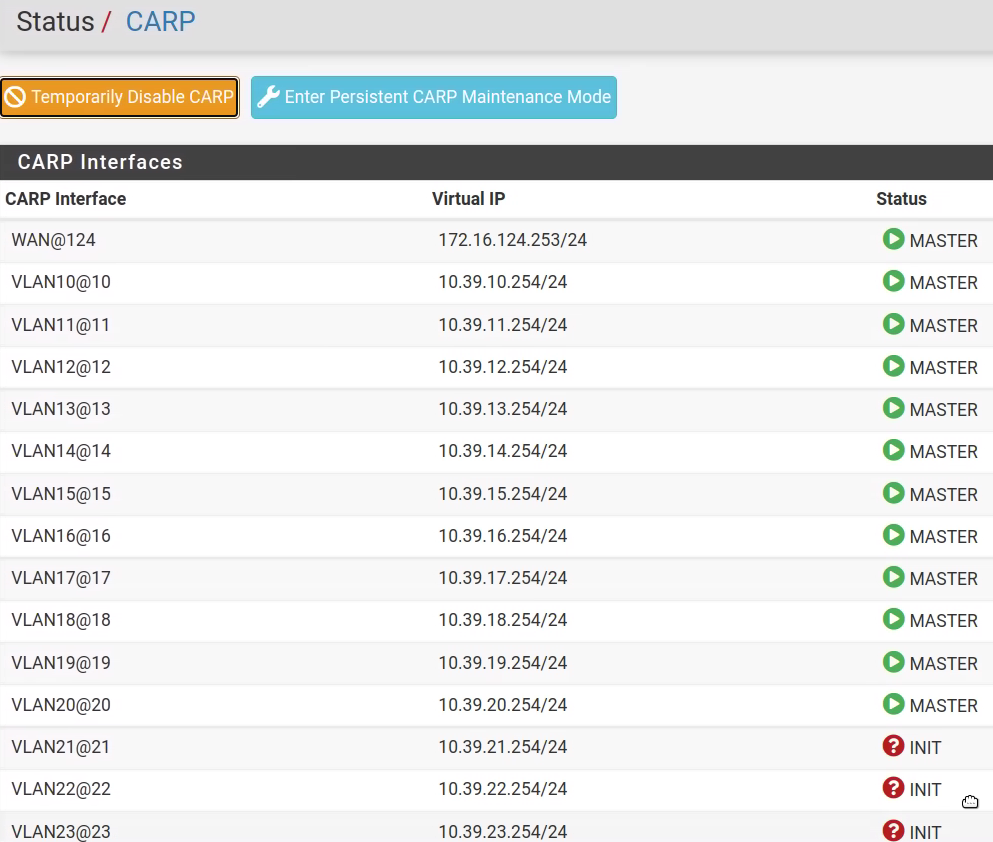
- HA cluster were unstable - some ports of Primary were Master, then they became Backup and then Master again. I always got 'CARP has detected a problem and this unit has a non-zero demotion status...' messages. Step by step, after each pressing 'Reset CARP Demotion Status' the amount of VLAN CARP VIPs in INIT state became less and less ('after_about_10_minutes.png')
Primary node continued to switch to Backup mode and back again and again.
- and after about 20 minutes all VLAN CARP VIPs on Primary became Master and HA cluster became stable.
- pressing Save (without changing anything) for LAGG port, while HA cluster were unstable, change nothing (it didn't make HA cluster stable).
- after rebooting Primary node just after changing LAGG type on it (and getting unstable HA cluster), all VLAN CARP VIPs became Master and HA cluster became stable.
Updated by Azamat Khakimyanov over 3 years ago
Tested on 22.05.
I restored the same HA cluster on current 22.05 and got the same result - after changing LAGG type HA cluster became unstable with lots of VLAN CARP VIPs in INIT state and then after 10-15 minutes HA cluster returned to normal.
These tests were made on Linux KVM (Intel i5-11400 with 24Gb of RAM and 512 Gb SSD, Ubuntu 22.10).
VMs had 4CPUs and 4Gb of RAM.
KVM doesn't support LACP, so I used switching between Failover and LoadBalance LAGG modes.
 Updated by Marcos M over 2 years ago
Updated by Marcos M over 2 years ago
- Is duplicate of Bug #9453: Reconfiguring a parent LAGG interface breaks its VLANs added