Bug #11836
open
FRR ACCEPTFILTER shows out of order prefix-list
0%
Description
Adding entries to the ACCEPTFILTER prefix-list creates erratic behavior within the FRR running configuration.
Have a look at my notes in "show running-configuration output.txt" and you'll see the configuration is constantly changing.
Leave it for hours and it'll still keep cycling.
This makes the FRR process unstable and leads to routes sporadically going inactive (which were not inactive beforehand). Example:
firewall1.home.arpa# show ip route
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
K>* 0.0.0.0/0 [0/0] via 100.0.1.1, em0, 04:20:57
K * 10.1.194.0/24 [0/0] via 10.1.194.2 inactive, 04:20:57
C>* 10.1.194.0/24 [0/1] is directly connected, ovpns1, 04:20:57
O 10.2.194.0/24 [110/20] via 10.255.1.2, ovpns2 inactive onlink, weight 1, 04:20:36 ### should not be inactive!!! VPN users behind firewall2
C>* 10.255.1.2/32 [0/1] is directly connected, ovpns2, 04:20:57
C>* 10.255.2.2/32 [0/1] is directly connected, ovpns3, 04:20:57
C>* 100.0.1.0/30 [0/1] is directly connected, em0, 04:20:57
C>* 100.0.2.0/30 [0/1] is directly connected, em2, 04:20:57
O 192.168.1.0/24 [110/4] is directly connected, em1 inactive, weight 1, 04:20:57 ## this is fine - LAN of firewall1
C>* 192.168.1.0/24 [0/1] is directly connected, em1, 04:20:57
O 192.168.2.0/24 [110/8004] via 10.255.1.2, ovpns2 inactive onlink, weight 1, 04:20:37 ## should not be inactive!! LAN of firewall2
C>* 192.168.57.0/24 [0/1] is directly connected, em3, 04:20:57
firewall1.home.arpa#
The topology diagram for this lab is logged in [[https://redmine.pfsense.org/issues/11835]].
I'm using the exact same topology as that for this issue, but enabling the options that trigger this ACCEPTFILTER problem.
In my production environment I have the same basic topology (simplified for fault analysis), but I also have downstream OSPF routers behind "firewall1" LAN.
I thus generate a default route on firewall1 and flood that out the LAN.
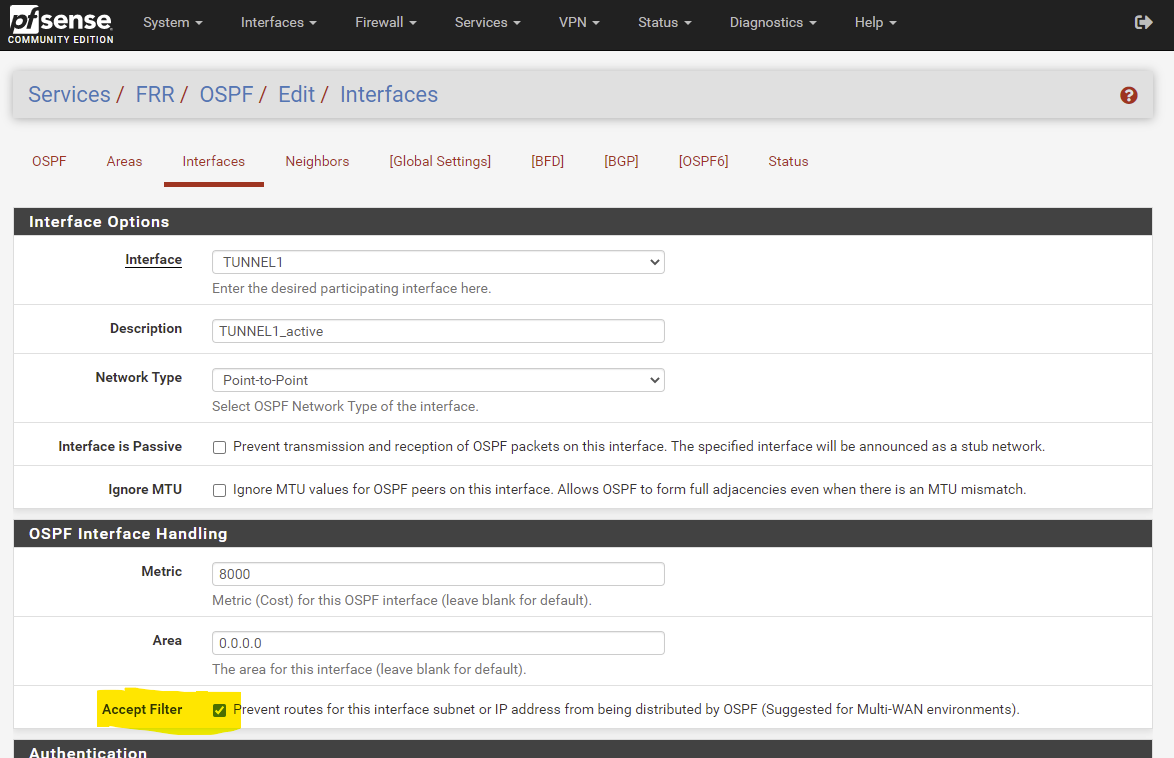
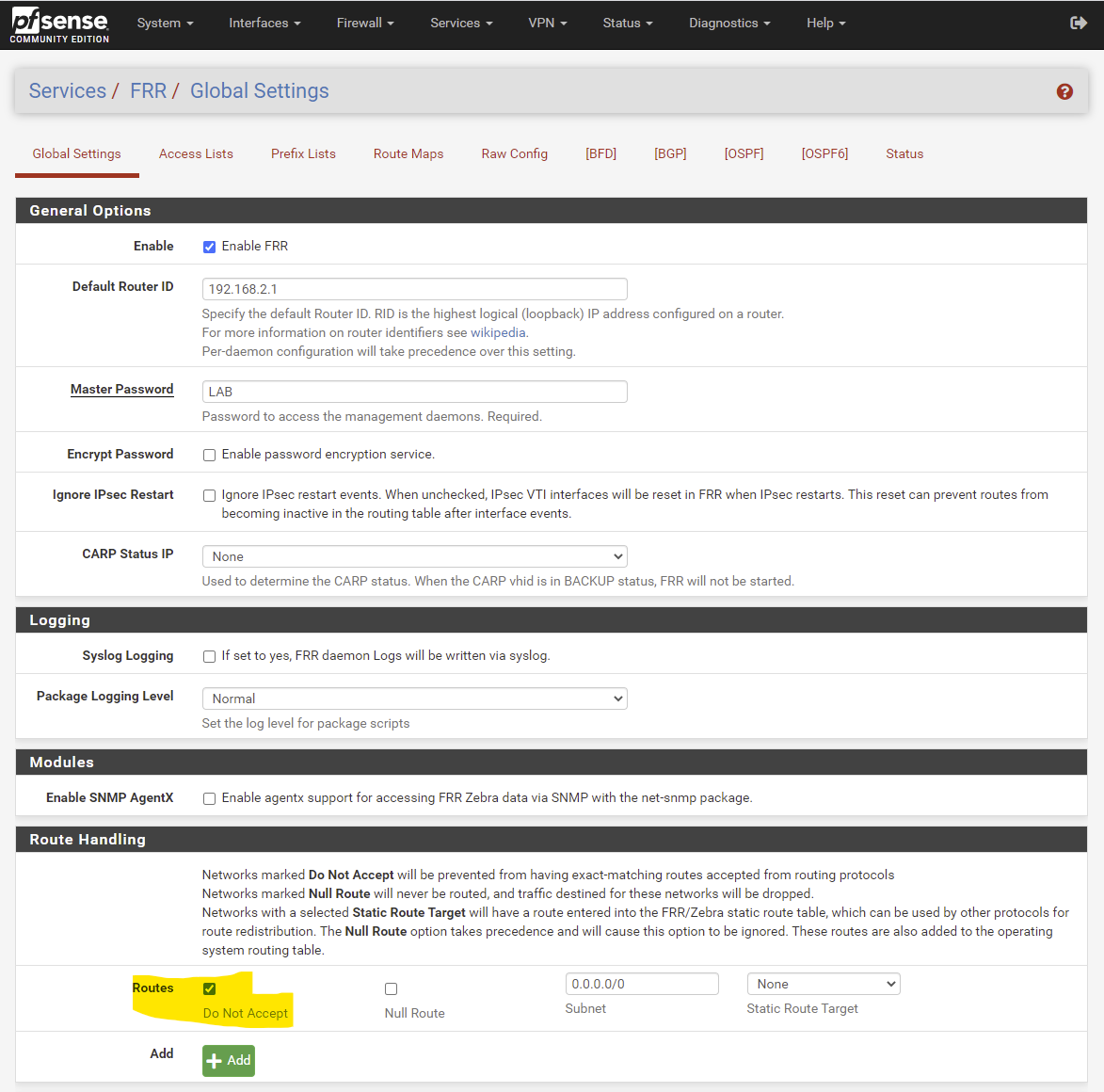
Over on my "firewall2" - that has its own default route being an Internet fireall, and it doesn't need firewall1's default. So, I use the option #2 above of filtering 0.0.0.0/0 in the global settings - see screenshot "FRR Global ACCEPTFILTER.png".
This all seemed to work on older versions of pfSense such as 2.4.5p1, so looks to be a regression (feel free to confirm but don't have a non-production 2.4.5p1 lab setup anymore).
The combination of enabling both of these filtering methods at the same time (interface "Accept Filter" and global configuration "Routes: Do Not Accept") is pretty catastrophic - for me the vtysh locks up completely. Even trying the new option "Force Service Restart" will not allow FRR to run. The only fix then is to reboot the whole pfSense node, and then undo those settings - followed by another reboot for good measure.
This may account for some of the horror stories told to me on the pfsense subreddit, from OSPF users upgrading into the 2.5.x releases (issue #11835 was occuring in earlier releases).
Files
{kind=link}
{kind=link}
Related issues
 Updated by Jim Pingle over 5 years ago
Updated by Jim Pingle over 5 years ago
- Project changed from pfSense to pfSense Packages
- Category changed from Routing to FRR
- Release Notes deleted (
Default)
 Updated by Viktor Gurov over 4 years ago
Updated by Viktor Gurov over 4 years ago
- Status changed from New to Feedback
Unable to reproduce on FRR 1.1.1_2:
ip prefix-list ACCEPTFILTER deny 192.168.89.0/24 ip prefix-list ACCEPTFILTER deny 192.168.89.100/32 ip prefix-list ACCEPTFILTER seq 10 deny 10.4.4.0/30 ip prefix-list ACCEPTFILTER seq 20 deny 172.16.7.0/24 ip prefix-list ACCEPTFILTER seq 30 permit any
Accept Filter sequence step is 10, not 5 as in your "show run":
https://github.com/pfsense/FreeBSD-ports/blob/devel/net/pfSense-pkg-frr/files/usr/local/pkg/frr/inc/frr_zebra.inc#L724
Please provide more information
 Updated by Matthew D over 4 years ago
Updated by Matthew D over 4 years ago
I am reproducing this issue (constantly changing FRR running configuration leading to inactive routes) and unfortunately, it's still present in 2.6RC. I'm not sure if it's relevant, but we're trying to send/receive OSPF routes over an OpenVPN tunnel. Our setup worked great with 2.4.5_p1 and several previous versions, but firewalls upgraded to 2.5.x have had issues with routes occasionally going inactive in the Zebra table and thus not being in the system routing table presumably due to this issue and probably some WAN instability mixed in. I can get things back to a working state by restarting FRR Zebra (or interestingly enough if I go to Raw Config and hit "Update Running Config", that stabilizes things as well), but obviously that's manual and shouldn't be necessary.
I have a TAC case open about the issue right now as well because staying on old versions isn't something we want to do forever. They confirmed (as is seen in Jim Pingle's Dynamic Routing with FRR Hangout) that having ACCEPTFILTER checked on both my LAN interface and the OpenVPN interface is advisable. They also recommended adding my VPN network as a static localhost route under FRR Global/Zebra Route Handling which I did, but it wasn't helpful to avoid the bad behavior. They suggested trying 2.6 RC, but the behavior is the same.
I am reproducing it by inserting a switch in between the WAN interface of my pfSense box and my actual WAN connection (cable modem). To reproduce, I disable the interface on the switch that the cable modem is hooked to and reboot the firewall. Once its up, I took a peak at the show running-configuration in vtysh and it was stable. Upon re-enabling the cable modem connection, the routes I expect to populate end up in Zebra, but Inactive and they are NOT placed into the system routing table. At this point, looking at show running configuration repeatedly shows the ACCEPTFILTER section constantly changing and it never settles until I restart Zebra.
I'm happy to provide what I can to try to get it fixed. I thought sharing my method for reproducing it VERY consistently might be helpful and I'm happy to provide additional information that would be helpful. I'm not a developer or an OSPF/FRR expert, but I do have a test setup specifically for this right now and I'm happy to work with someone.
 Updated by Marcos M over 4 years ago
Updated by Marcos M over 4 years ago
Regarding ACCEPTFILTER, you can test the patch here listed on #11686
Updated by Viktor Gurov over 4 years ago
- Related to Bug #11686: FRR generated ACCEPTFILTER permit statement broken added
 Updated by Azamat Khakimyanov over 4 years ago
Updated by Azamat Khakimyanov over 4 years ago
- File sh_run_output.txt sh_run_output.txt added
- Status changed from Feedback to Assigned
- Assignee set to Viktor Gurov
Tested on 22.01-RELEASE (built on Mon Feb 07 16:37:59 UTC 2022) with patch from Bug #11686 applied.
I still see that every time I run 'show run' lines for 'ip prefix-list ACCEPTFILTER' change its order (see 'sh_run_output.txt') and in 'show ip route' output I see 'inactive' for directly attached routes which were marked as 'Passive' for OSPF:
pfSense.mydomain.local# sh ip route
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
K>* 0.0.0.0/0 [0/0] via 192.168.122.1, vtnet0, 00:04:21
C>* 10.10.87.1/32 [0/1] is directly connected, ovpnc1, 00:04:21
O 172.31.25.0/24 [110/10] is directly connected, vtnet2 inactive , weight 1, 00:04:20
C>* 172.31.25.0/24 [0/1] is directly connected, vtnet2, 00:04:21
O>* 172.31.87.0/24 [110/20] via 10.10.87.1, ovpnc1 onlink, weight 1, 00:04:12
O 192.168.25.0/24 [110/10] is directly connected, vtnet1 inactive , weight 1, 00:04:20
C>* 192.168.25.0/24 [0/1] is directly connected, vtnet1, 00:04:21
O>* 192.168.87.0/24 [110/20] via 10.10.87.1, ovpnc1 onlink, weight 1, 00:04:12
C>* 192.168.122.0/24 [0/1] is directly connected, vtnet0, 00:04:21
So it's not an issue, it's just mean that these interfaces are Passive in OSPF. And I see these routes on remote peer
pfSense.mydomain.local# sh ip route ospf
O>* 172.31.25.0/24 [110/20] via 10.10.87.2, ovpns1 onlink, weight 1, 00:02:29
O>* 192.168.25.0/24 [110/20] via 10.10.87.2, ovpns1 onlink, weight 1, 00:02:29
So t's now much more stable on 22.01-RELEASE with patch applied but it's a bit weird that line's order for ip prefix changes every time I run 'sh run' command.
And I thought about this ACCEPTFILTER and I think we should delete this option for OSPF.
Getting your own routes back from remote peer can cause issue when you use BGP/RIP but it's not an issue for OSPF.
Updated by Matthew D over 4 years ago
It looks to me like, with the patch, the "seq xx" numbering has been corrected so that the "permit any" is always the highest number which should place it at the end, however, I'm also still seeing the weird constantly changing/cycling config in VTYSH when doing show running-configuration where it looks like the permit any keeps moving up through the other entries. I'm unsure if this has any impact on stability, but it is definitely weird and seems not right. I originally complained about this issue because I'd have a situation where all of my remote routes would end up as Inactive and therefore no way to get to them. That's what I am trying to avoid. Maybe leaving ACCEPTFILTER unchecked is the answer, but the Jim Pingle Hangout and TAC have guided me to check it for both LAN networks and VPN tunnel networks.
 Updated by Gavin Owen almost 4 years ago
Updated by Gavin Owen almost 4 years ago
Matthew D wrote in #note-7:
It looks to me like, with the patch, the "seq xx" numbering has been corrected so that the "permit any" is always the highest number which should place it at the end, however, I'm also still seeing the weird constantly changing/cycling config in VTYSH when doing show running-configuration
Am seeing the same thing as you and thinking the same thing. The ACCEPTFILTER seems to be working correctly for me now, but the output of the prefix-list is still weird.
Here's a grab from my "show running-config":
ip prefix-list CONNECT seq 10 permit 10.27.194.0/24
ip prefix-list ACCEPTFILTER seq 50 deny 10.255.197.0/30
ip prefix-list ACCEPTFILTER seq 60 deny 10.255.197.1/32
ip prefix-list ACCEPTFILTER seq 70 permit any
ip prefix-list ACCEPTFILTER seq 10 deny 10.255.195.0/30
ip prefix-list ACCEPTFILTER seq 20 deny 10.255.195.1/32
ip prefix-list ACCEPTFILTER seq 30 deny 10.255.196.0/30
ip prefix-list ACCEPTFILTER seq 40 deny 10.255.196.1/32
!
Run it again I get:
ip prefix-list CONNECT seq 10 permit 10.27.194.0/24
ip prefix-list ACCEPTFILTER seq 60 deny 10.255.197.1/32
ip prefix-list ACCEPTFILTER seq 70 permit any
ip prefix-list ACCEPTFILTER seq 10 deny 10.255.195.0/30
ip prefix-list ACCEPTFILTER seq 20 deny 10.255.195.1/32
ip prefix-list ACCEPTFILTER seq 30 deny 10.255.196.0/30
ip prefix-list ACCEPTFILTER seq 40 deny 10.255.196.1/32
ip prefix-list ACCEPTFILTER seq 50 deny 10.255.197.0/30
It's not actually random. No matter how log I wait - the next time I run "show running-config", the "seq 10" moves up one, and the entry that was previously listed first (seq 50 in my example), wraps around to the bottom. It might be just cosmetic, but a proper display output should always show that "seq 10" entry first.
Updated by Gavin Owen almost 4 years ago
When I generate the FRR config via the GUI, it actually formats and displays the ACCEPTFILTER correctly, so the above just seems to be a weird CLI display issue.
Updated by Marcos M almost 4 years ago
- Subject changed from FRR ACCEPTFILTER unstable to FRR ACCEPTFILTER shows out of order prefix-list
- Status changed from Assigned to Confirmed
- Assignee deleted (
Viktor Gurov) - Affected Version deleted (
2.5.x)