Bug #4081
closed
Apinger reporting incorrect latency
0%
Description
If a gateway has an explicit monitor address, apinger will stop reporting latency to the monitor address and switch to reporting latency for the gateway address. Very obvious if the gateway address is local (~ 1ms) and the monitor address is across a remote link (~10ms). Once the switch occurs, apinger appears to remain stuck reporting the lower value.
It's notable that (hours) after the event, the pings are going to the correct (monitor) address even though the latency being reported corresponds to the local gateway address.
It's unclear what the trigger for this is. I haven't caught the event live yet. I have a tcpdump running in hopes of catching the event live.
Files
| pfsense 4081.jpg (68.6 KB) pfsense 4081.jpg | RTT drop | ||
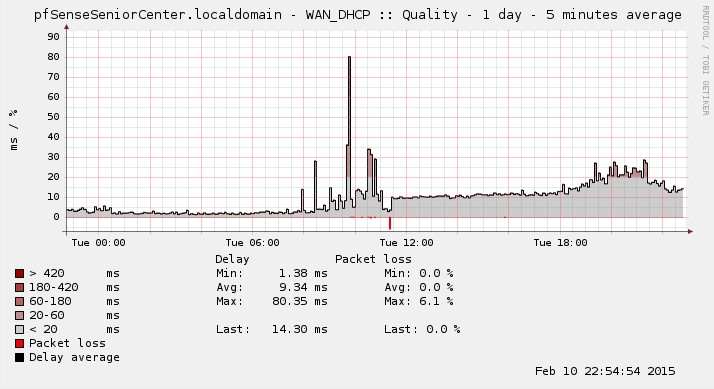
| pfsense 4081 fix.jpg (69 KB) pfsense 4081 fix.jpg | RTT "fix" with cable modem/nic reset |
 Updated by Michael Kellogg over 11 years ago
Updated by Michael Kellogg over 11 years ago
I have a bare metal box that I believe this or something related is happing chris has access info if any of the other devs want to look at it
 Updated by Chris Buechler over 11 years ago
Updated by Chris Buechler over 11 years ago
- Category set to Gateway Monitoring
- Status changed from New to Confirmed
it's not reporting latency to the gateway, its calculations become wrong under some circumstance.
Updated by Michael Kellogg over 11 years ago
also affects rrd graph at same time
Updated by Michael Kellogg over 11 years ago
with this about 20% of the time causes a mail storm makes the box inaccessible from webgui a reset of web configurator doesn't help it seems to require a reboot to recover
Updated by Michael Kellogg over 11 years ago
could this issue be aggravated by using google dns as monitor addresses as they are anycast?
 Updated by Stuart Wyatt over 11 years ago
Updated by Stuart Wyatt over 11 years ago
- File pfsense 4081.jpg pfsense 4081.jpg added
- File pfsense 4081 fix.jpg pfsense 4081 fix.jpg added
I had this problem on a clean plain install of 2.2 using a cable modem DHCP WAN with no explicitly set or override of the gateway monitor.
When it occurs, the RTT value drops to about 10-20% of the actual value but continues to follow the actual value proportionally.
I was able to "fix" it by rebooting the cable modem or disconnecting and reconnecting the WAN interface cable. I couldn't correlate anything with the trigger.
I've attached RDD graphs of it occurring and the "fix"
Updated by Chris Buechler over 11 years ago
- Target version changed from 2.2.1 to 2.2.2
Updated by Chris Buechler over 11 years ago
- Target version changed from 2.2.2 to 2.2.3
 Updated by Heiler Bemerguy over 11 years ago
Updated by Heiler Bemerguy over 11 years ago
I have this bug here. It screws up our Multi-WAN setup. Ideally we should use losses/highping to switch gateways, but as these data are almost always wrong/surreal, we disabled it. The only temporary fix I've seen is restarting apinger service every 5-10 minutes :/
Updated by Heiler Bemerguy over 11 years ago
I must add that this always happened, with 2.1.4, 2.1.5, 2.2.0, 2.2.1 and 2.2.2. In a XEN or VMWare environment.
Updated by Stuart Wyatt over 11 years ago
I never saw this happen on several 2.1.5 installs but it happened on every (3) 2.2.0 install I tried.
I'll have a test machine I can connect to a cable modem next week in hopes to track this problem down. I've been reviewing the code and have some things to look for when it gets into this state. I need reliable latency and loss tracking so this is a high priority bug for me.
Updated by Heiler Bemerguy about 11 years ago
Sending ping #1584 to GWPDP (200.160.6.214)
Recently lost packets: 0
Sending ping #3607 to GWEBT (200.230.251.210)
Recently lost packets: 0
Polling, timeout: 0.999s
#3607 from GWEBT delay: 52.327ms/43.812ms/496.876ms received = 3360
(avg: 49.688ms)
(avg. loss: 0.0%)
Polling, timeout: 0.947s
#1584 from GWPDP delay: 67.941ms/65.886ms/658.732ms received = 1577
(avg: 65.873ms)
(avg. loss: 0.0%)
Polling, timeout: 0.931s
Sending ping #1585 to GWPDP (200.160.6.214)
Recently lost packets: 0
Sending ping #3608 to GWEBT (200.230.251.210)
Recently lost packets:* 1*
Why did it increment GWEBT loss from 0 to 1 if it received the ping sucessfully ?
Updated by Chris Buechler about 11 years ago
- Status changed from Confirmed to Needs Patch
- Target version deleted (
2.2.3)
apinger is being replaced in 2.3, which will resolve outstanding issues here.
Updated by Michael Kellogg over 10 years ago
this does not show up to be tracked for 2.3
 Updated by George Koflis over 10 years ago
Updated by George Koflis over 10 years ago
Only workaround is cron job every 3-5 minutes or so when is apinger update version gonna be released any idea?
 Updated by Jeppe Oland over 10 years ago
Updated by Jeppe Oland over 10 years ago
For me, apinger suddenly goes from 5ms to 50ms.
Restarting it recovers.
Updated by Chris Buechler over 10 years ago
- Status changed from Needs Patch to Resolved
- Target version set to 2.3
- Affected Version changed from 2.2 to All
fixed in 2.3 by replacing apinger
 Updated by
Updated by 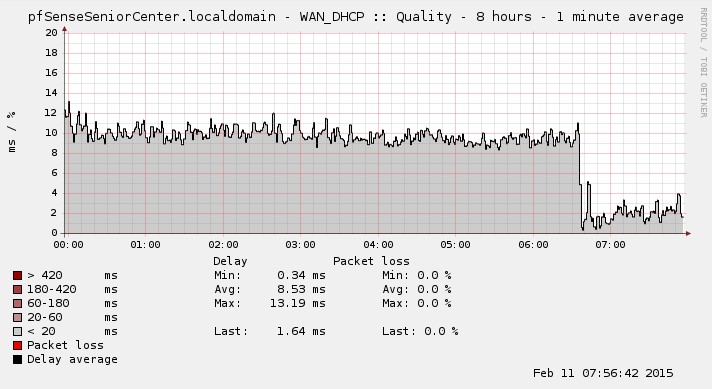{kind=link}
{kind=link}
Updated by Chris Buechler over 10 years ago
Thank you, Denny. Appreciate the help getting rid of our apinger woes. I've been through a variety of test scenarios that used to make apinger lose its mind and fail basic math, and have yet to find any inaccuracies in dpinger output.