Bug #10414
closed
Very high CPU usage of pfctl and more causing very high load and a hardly usable internet connection
100%
Description
There are several threads in the forum complaining about high CPU usage of pfctl and some other processs. This is causing a long boot time, unbelievable high ping times of the gateway monitoring, slow or not responding web interface and huge problems with the internet connection (package loss, slow response, ...).
The main thread about the problem can be found here: https://forum.netgate.com/topic/151690/increased-memory-and-cpu-spikes-causing-latency-outage-with-2-4-5
but others are:
https://forum.netgate.com/topic/151726/pfblockerng-2-1-4_21-totally-lag-system-after-pfsense-upgrade-from-2-4-4-to-2-4-5
https://forum.netgate.com/topic/151921/pfsense-2-4-5-hohe-last-ipv6
https://forum.netgate.com/topic/151949/2-4-5-new-install-slow-to-boot-on-hyper-v-2019/11
...
Steps to reproduce:
- update to 2.4.5 or do a fresh install
- use a value of >65535 for "Firewall Maximum Table Entries"
- enable bogons filtering
- pass some traffic through the firewall
- wait - for me it sometimes takes just a few seconds, sometimes several hours until the problem occurs
Effects:
- slower boot times (on a fresh install: not at the first boot, maybe only after the bogons table has been updated?)
- slow response of the web interface
- high cpu usage, mostly at 100%, even on a very high performance machine (Xeons or Epycs/Ryzens with dozen(s) of cores)
- dropped packages and high ping times, internet connection is hardly usable because of the package loss, voice calls stutter
- "System Activity" is hardly responding, but if it does it shows pfctl and more processes to eat up all CPU. For me a second process is dpinger and sometimes unbound, but others reported other processes, for example ntpd. The main problem seems to be related to pfctl
- some reports show an increased memory usage as well
Cause:
- it may be related to this: https://www.freebsd.org/security/advisories/FreeBSD-EN-20:04.pfctl.asc but what's really causing the issue is maybe unknown?
Workaround:
- disable "Block bogon networks" on all interfaces
- and then set "Firewall Maximum Table Entries" in "System | Advanced | Firewall & NAT" to a value less then 65535
-> now pfsense 2.4.5 is usable again without high load/usage and without drops/lags
Files
 Updated by Tobias H over 6 years ago
Updated by Tobias H over 6 years ago
A few additions:
- it seems to happen more often if pfSense is installed and used in a virtual environement
- it seems to happen more often if aliases are used in the firewall rules
- it seems to happen more often if a large ruleset is used, for example if pfBlockerNG is used and/or IPv6 with bogons block
- it seems to happen rarely if pfSense is installed in a single core environment
 Updated by Jim Pingle over 6 years ago
Updated by Jim Pingle over 6 years ago
- Category set to Operating System
Likely the same root cause as #10310 though that doesn't have quite the same symptoms.
Cause:
- it may be related to this: https://www.freebsd.org/security/advisories/FreeBSD-EN-20:04.pfctl.asc but what's really causing the issue is maybe unknown?
2.4.5 already includes that. We found it and raised the issue with FreeBSD directly. Check the "Credits" line and #10254
That change only added the tunable which allows transactions to exceed 65k in size. The code which enacted that limit was already in 11.3 and not directly related to that change. Without it, loading more than 65k table entries was not possible.
Those changes were already in 2.5.0, too, but it does not show the same symptoms (at least none have reported them). See #9356
Thus far we haven't been able to reproduce this locally in our lab and test systems other than the minor observed behavior in #10310
 Updated by John Jacobs over 6 years ago
Updated by John Jacobs over 6 years ago
I can reproduce this at will. My hardware is a Supermicro 5018D-FN4T (Same as XG-1541). I can provide a config file if you have matching hardware in your test lab. I will add that the larger the total number of items in tables the more obvious the issue is but the issue is present (look at pfctl cpu usage compared to 2.4.4-p3) even when below the 65k hardlimit removed by #10254. Try a config with 250,000 or more total items and you can't miss the pfctl cpu spike and the resulting latency and packet loss when reloading tables.
 Updated by W M over 6 years ago
Updated by W M over 6 years ago
I can confirm this problem. If there are changes to the routing table (because there is packet loss on some OpenVPN Interface or other) these firewall table reloads are triggered.
I have already attached pictures on this topic in my post - https://forum.netgate.com/topic/151921/pfsense-2-4-5-hohe-last-ipv6
The problem concerns 2 pfSense installations at my site and also the pfSense in our company is affected. On all of them IPv6 is active.
Is it possible that the IPv6 bogon list is simply too large to be processed on the pfSense?
 Updated by Wesley Kirby over 6 years ago
Updated by Wesley Kirby over 6 years ago
- File IMG-0139.jpg IMG-0139.jpg added
I can verify this issue.
CPU Type Intel(R) Xeon(R) CPU E5645 @ 2.40GHz
12 CPUs: 2 package(s) x 6 core(s)
Memory usage
7% of 22467 MiB
Version 2.4.5-RELEASE (amd64)
built on Tue Mar 24 15:25:50 EDT 2020
FreeBSD 11.3-STABLE
Symptoms:
Randomly and for no more than a few seconds at a time, CPU usage will spike causing latency on all ports. I have a desktop plugged into one port and pinging the gateway port (pfSense Router), will spike to 3500ms once or twice, or even a timeout or two.
While ssh in, I was able to snap a picture where it shows pfctl and dpinger and sshd spiking in CPU usage. I believe sshd spike was only a byproduct of pfctl spiking. It happens randomly, sometimes happening a few times a minute, sometimes hours in between.
 Updated by
Updated by 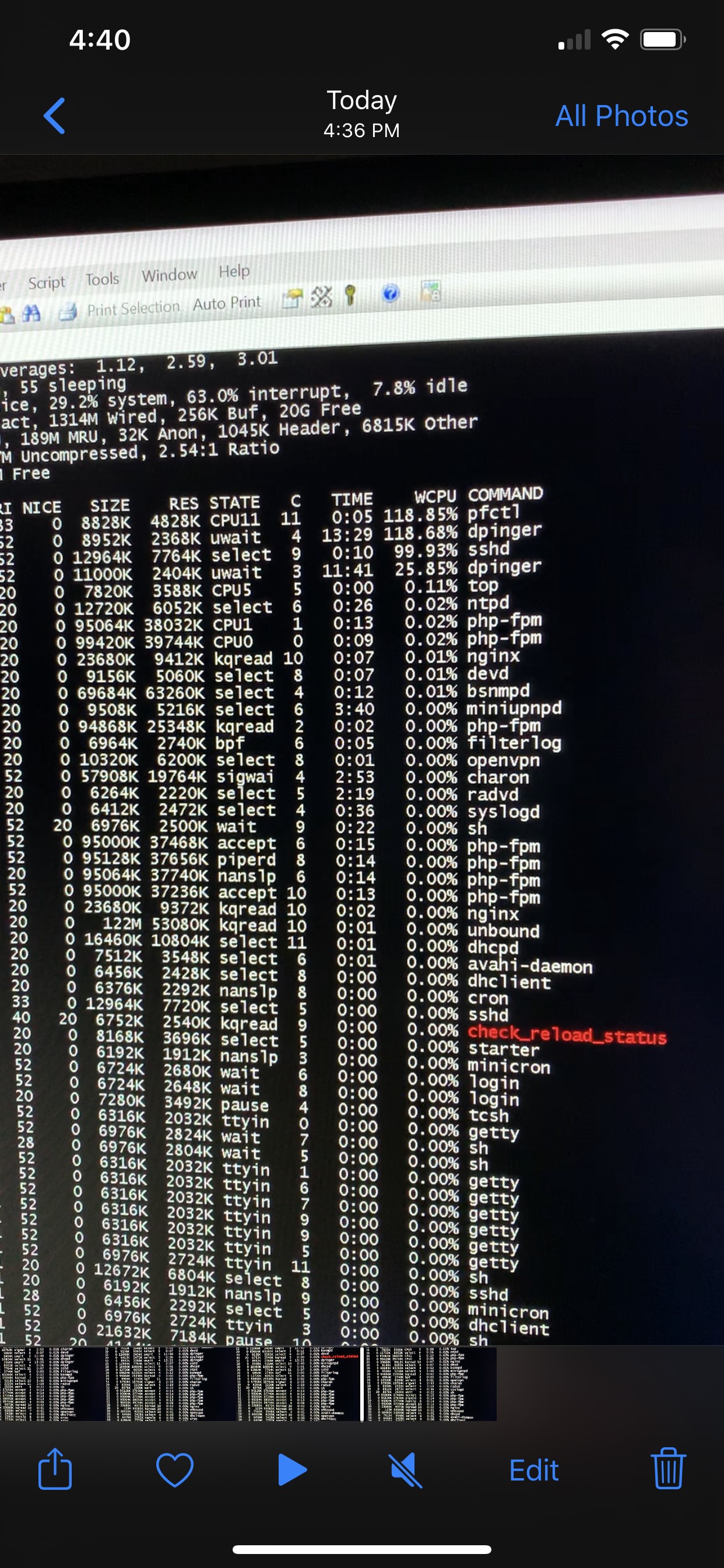{kind=link}
 Updated by Benoit Lelievre over 6 years ago
Updated by Benoit Lelievre over 6 years ago
I've had to revert back to 2.4.4-p3 because the workaround doesn't work if you need to keep using pfBlockerNG. There aren't enough Firewall table entries to operate normally.
 Updated by Jordan Brandon over 6 years ago
Updated by Jordan Brandon over 6 years ago
I am having the same issue here running pfsense on Proxmox. Enabling pfBlocker makes the network unusable as the CPU goes to 100% (16 cores on a DL380) and the gateway ping time approached 4000ms.
 Updated by Chris F over 6 years ago
Updated by Chris F over 6 years ago
Not much to add, but getting same issue.
Not virtual - SG3100.
IPV6 enabled.
Snort + Pfblocker enabled.
Bogan block on.
Handful of manual rules - most are pfblocker country blocks.
During CPU spikes I can't ssh or use web interface. DNS down, however I can ping.
Also get "/tmp/rules.debug:23: cannot define table bogonsv6: Cannot allocate memory" error too.
 Updated by Manfred Bongard over 6 years ago
Updated by Manfred Bongard over 6 years ago
+1
in my case it is the Filter Reload. I had this high CPU load every 15 minutes. All cores go to 100% for seconds. No packets lost but 4000-5000ms delay. VoIPs and VPNs were crashed.
So i found that the cron job "/etc/rc.filter_configure_sync" was the cause.
My workaround: I changed this job to midnight and rule changes are only out site of business hours. Now the 60 Ipsec-tunnls where stable again. But this is not the solution
Environment:
pfblocker with GeoIP selections
snort
FRR
CARP
Traffic Shaper
IPv6 disabled
Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz
20 CPUs: 1 package(s) x 10 core(s) x 2 hardware threads
 Updated by Roger Colunga over 6 years ago
Updated by Roger Colunga over 6 years ago
So I have the same issue on a Netgate SG3100. It starts when you enable multiple GeoIP regions on pfblockerng for my firewall. Once you start seeing that "cannot allocate memory" error no matter what max tables settings you do you will start seeing weird browser slow downs and potentially other symptoms. Even if you remove regions and reload pfblockerng it will still give you the error and symptoms.
What I had to do is disable all GeoIP regions with the exception of the items (PRI) that get enabled using the wizard, I also reverted any states or max table changes to the defaults and then perform a reboot of firewall. Once it reboots you should not see that error. you can then enable maybe top spammers and that is it. If you try to enable more regions etc well you most likely will start seeing the problems and errors. Reverting back to 2.4.4 was not an option for me since I had not made a backup before the 2.4.5 update. Hopefully this helps someone else that is having the same issues and is using pfblockerng.
Updated by Jim Pingle over 6 years ago
- Assignee set to Luiz Souza
We have identified the cause of the problem, it is a change made in FreeBSD for a PR: https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=230619
On a test kernel with r345177 reverted, there is no delay, lock, or other disruption on a multi-core Hyper-V VM:
: pfctl -t bogonsv6 -T flush 111171 addresses deleted. : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 111171/111171 addresses added. 0.149u 0.196s 0:00.34 97.0% 373+192k 0+0io 0pf+0w : pfctl -t bogonsv6 -T flush 111171 addresses deleted. : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 111171/111171 addresses added. 0.175u 0.199s 0:00.37 97.2% 365+188k 0+0io 0pf+0w
On a stock 2.4.5 kernel that same system experienced a 60-second lock where the console and everything else was unresponsive.
We're still assessing the next steps.
Updated by Jim Pingle over 6 years ago
- Status changed from New to Feedback
Luiz said the corrections have been made in the src tree
 Updated by → luckman212 over 6 years ago
Updated by → luckman212 over 6 years ago
For people suffering from this now, until the next release, this might help:
add the line below to /boot/loader.conf.local and reboot
kern.smp.disabled=1
ref: https://forum.netgate.com/post/909168
 Updated by Luiz Souza about 6 years ago
Updated by Luiz Souza about 6 years ago
- % Done changed from 0 to 100
Fix committed.
Snapshots with this fix will be available soon (for general testing).
Updated by → luckman212 about 6 years ago
Thx Luiz! this is the commit, right?
https://github.com/pfsense/FreeBSD-src/commit/6c7a5a8e69762db2ac0bc465f37c8f04a45a34ea#diff-cfe1b9af5640485f16600f6f505ad7a5
Just wondering, is this just a straight rollback of the original FreeBSD PR#230619? It only applies to the FreeBSD 11/2.4.5 branches right, not 12/2.5.0? Reading the description of the original commit, seems like it was an important race condition fix. Or do I mis-understand?
 Updated by Jim Thompson about 6 years ago
Updated by Jim Thompson about 6 years ago
Luke,
From what we can tell, pf is doing a ton of smp rendezvous zeroing per-CPU counters. The described "hang" seems (mostly) caused by a ton of back-to-back IPIs. As you noted, disabling SMP makes the issue go away.
All of that said, the issue seems to be present upstream, and it's likely deeper than just #230619.
Updated by Jim Pingle about 6 years ago
A proposed fix: https://reviews.freebsd.org/D24803
 Updated by Renato Botelho about 6 years ago
Updated by Renato Botelho about 6 years ago
Imported markj@ fix to 2.5.0
https://svnweb.freebsd.org/base?view=revision&revision=360903
Updated by Luiz Souza about 6 years ago
Luke Hamburg wrote:
Thx Luiz! this is the commit, right?
https://github.com/pfsense/FreeBSD-src/commit/6c7a5a8e69762db2ac0bc465f37c8f04a45a34ea#diff-cfe1b9af5640485f16600f6f505ad7a5Just wondering, is this just a straight rollback of the original FreeBSD PR#230619? It only applies to the FreeBSD 11/2.4.5 branches right, not 12/2.5.0? Reading the description of the original commit, seems like it was an important race condition fix. Or do I mis-understand?
Luke,
That is correct, but the race described in commit only affect the counter numbers (maybe a crash if you aren't lucky) but seems more difficult to happen than the current issue, the tradeoff seems to be worth at this moment. Also, this is a temporary fix while the real fix is being developed and tested.
Updated by Jim Pingle about 6 years ago
Testing a kernel with the original fix taken out (so r345177 restored), and the new fix applied, it still look good to me.
Same Hyper-V VM as before. No console lock, table loads fast, no CPU spike or persistent pfctl process.
: time pfctl -t bogonsv6 -T flush 111171 addresses deleted. 0.000u 0.066s 0:00.06 100.0% 373+192k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 111171/111171 addresses added. 0.172u 0.267s 0:00.44 97.7% 364+187k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 0/111171 addresses added. 0.190u 0.087s 0:00.27 100.0% 362+186k 0+0io 0pf+0w
We test more once we have RC snapshots.
Updated by Jim Pingle about 6 years ago
I was able to replicate this to a lesser extent on Proxmox VE (6.2-4) as well, with a 4-core VM. Similar setup to the Hyper-V test before. It wasn't as prominent here like on Hyper-V but it was still very noticeable.
Stock 2.4.5-RELEASE kernel:
: time pfctl -t bogonsv6 -T flush 112536 addresses deleted. 0.000u 0.101s 0:00.10 100.0% 364+187k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 112536/112536 addresses added. 0.259u 6.190s 0:06.45 99.8% 356+183k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 0/112536 addresses added. 0.239u 0.147s 0:00.38 97.3% 381+198k 0+0io 0pf+0w
Notice it took >6 seconds of real time here. Console wasn't unresponsive but the network did take a hit and ssh was lagging.
Kernel with the later fix applied:
: time pfctl -t bogonsv6 -T flush 112536 addresses deleted. 0.000u 0.073s 0:00.07 100.0% 360+185k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 112536/112536 addresses added. 0.251u 0.322s 0:00.57 100.0% 358+184k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 0/112536 addresses added. 0.252u 0.134s 0:00.38 100.0% 361+185k 0+0io 0pf+0w
Updated by Jim Pingle about 6 years ago
- Status changed from Feedback to Resolved
Both Hyper-V and Proxmox look good on our internal testing snapshots. Both test systems have 4 CPUs. Same systems from my previous notes, so both originally exhibited problems in different ways.
Same kernel on both:
: uname -a FreeBSD <blah> 11.3-STABLE FreeBSD 11.3-STABLE #240 abf8cba50ce(RELENG_2_4_5): Fri May 22 11:39:30 EDT 2020 root@buildbot1-nyi.netgate.com:/build/ce-crossbuild-245/obj/amd64/YNx4Qq3j/build/ce-crossbuild-245/sources/FreeBSD-src/sys/pfSense amd64
After upgrade, force a manual bogons update to re-populate the data:
/etc/rc.update_bogons.sh 0
Hyper-V:
: time pfctl -t bogonsv6 -T flush 112630 addresses deleted. 0.000u 0.085s 0:00.08 100.0% 385+198k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 112630/112630 addresses added. 0.118u 0.220s 0:00.33 100.0% 364+187k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 0/112630 addresses added. 0.163u 0.070s 0:00.23 100.0% 365+187k 0+0io 0pf+0w
Proxmox:
: time pfctl -t bogonsv6 -T flush 112630 addresses deleted. 0.007u 0.075s 0:00.08 87.5% 440+226k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 112630/112630 addresses added. 0.258u 0.329s 0:00.58 98.2% 368+189k 0+0io 0pf+0w : time pfctl -t bogonsv6 -T add -f /etc/bogonsv6 0/112630 addresses added. 0.243u 0.164s 0:00.40 100.0% 367+191k 0+0io 0pf+0w
Looks good to me. Closing it out.