Regression #12827
closed
High latency and packet loss during a filter reload
100%
Description
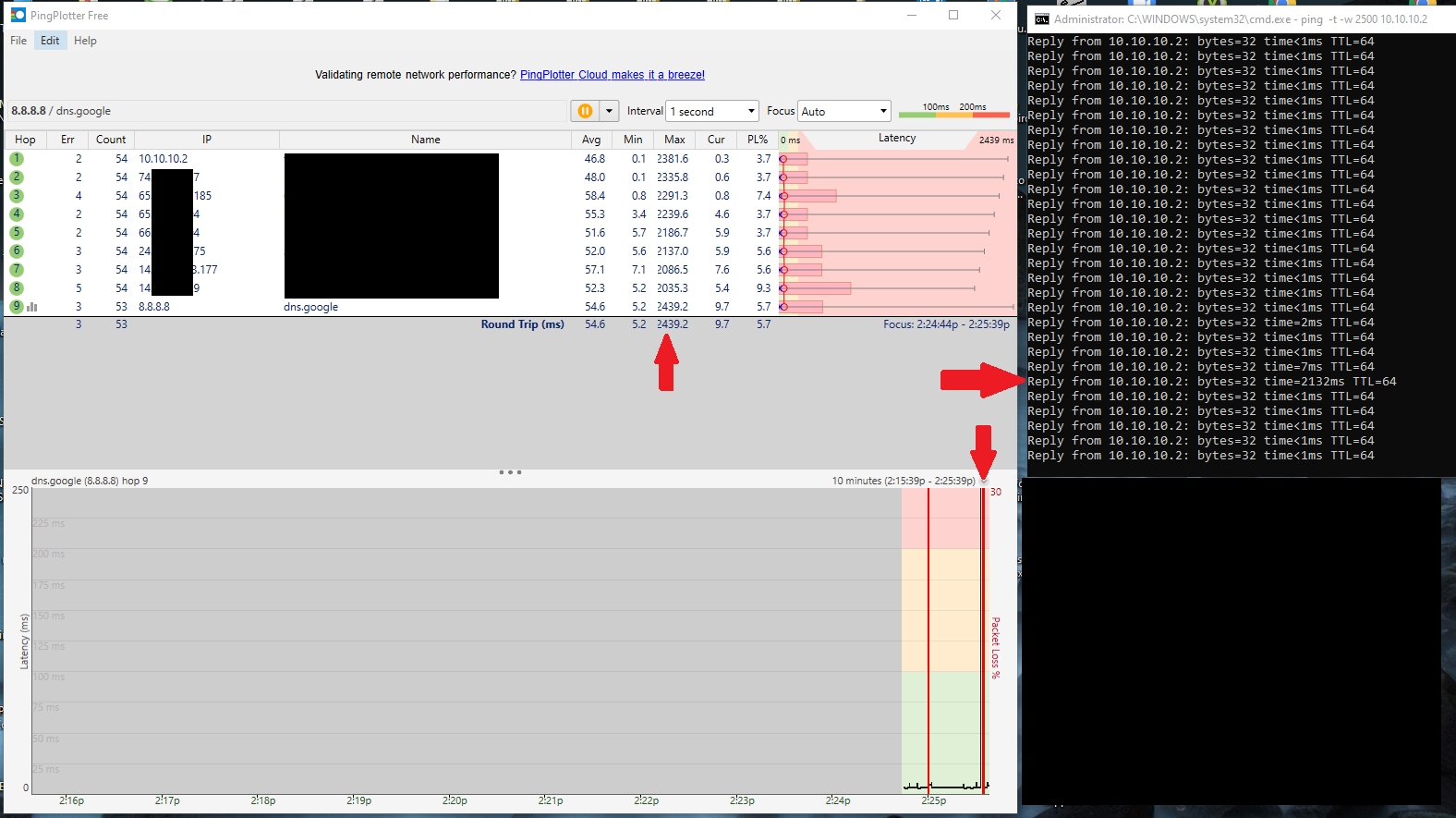
Every 15 minutes I am seeing 2 seconds latency that disrupts VPN, VoIP between sites, video conferencing, etc.
I have narrowed it down to the cronjob "/etc/rc.filter_configure_sync" that runs every 15 minutes.
The latency also occurs on demand when manually ran and also occurs with both of our HA appliances.
Files
{kind=link}
 Updated by Steve Wheeler over 4 years ago
Updated by Steve Wheeler over 4 years ago
- Tracker changed from Bug to Regression
- Subject changed from Major latency when /etc/rc.filter_configure_sync runs to High latency when reloading the ruleset
- Priority changed from Normal to High
- Target version set to Plus-Next
- Affected Architecture All added
- Affected Architecture deleted (
7100)
I have replicated this with a generated ruleset between 21.05.2 and 22.01:
[22.01-RELEASE][root@5100.stevew.lan]/root: pfctl -sr | wc -l
1121
[22.01-RELEASE][root@5100.stevew.lan]/root: time pfctl -f /tmp/rules.debug
0.520u 2.295s 0:02.81 100.0% 203+182k 1+0io 0pf+0w
[21.05.2-RELEASE][root@5100.stevew.lan]/root: pfctl -sr | wc -l
1116
[21.05.2-RELEASE][root@5100.stevew.lan]/root: time pfctl -f /tmp/rules.debug
0.302u 0.270s 0:00.57 100.0% 202+176k 0+0io 0pf+0w
Updated by Steve Wheeler over 4 years ago
- Project changed from pfSense Plus to pfSense
- Category changed from Unknown to Unknown
- Target version changed from Plus-Next to CE-Next
- Affected Plus Version deleted (
22.01) - Plus Target Version set to Plus-Next
- Affected Version set to 2.6.0
Updated by Steve Wheeler over 4 years ago
- Target version changed from CE-Next to 2.7.0
- Plus Target Version changed from Plus-Next to 22.05
 Updated by Kristof Provost over 4 years ago
Updated by Kristof Provost over 4 years ago
- Assignee set to Kristof Provost
I strongly suspect https://github.com/pfsense/FreeBSD-src/commit/a5a03901798c76f1f7c77535a2282a60f54b0ec2 is the main culprit here.
The easiest improvement will be to move this work out from the PF_RULE_WLOCK. That may affect the how accurately we copy over the counters, but a small inaccuracy there is far less of an issue than stalling traffic.
While we're looking at this we should also see if there's more work that can be moved out from the locked section.
 Updated by Michael Novotny over 4 years ago
Updated by Michael Novotny over 4 years ago
FYI. This latency also occurs when any rules, traffic shaper, etc. (anything that reloads the rules) are applied/modified, not just the scheduled cron.
 Updated by Fabio Giudici over 4 years ago
Updated by Fabio Giudici over 4 years ago
I can confirm that any rules roload introduces high latency. Even the shutdown of the sync interface (that as far as I can see fires a rule reload on the active member) gets this.
The version affected are both 2.6.0 and 22.01 plus.
We have an ha cluster who has 3960 rules that introduces like 20 seconds of latency for that...
 Updated by Flole Systems over 4 years ago
Updated by Flole Systems over 4 years ago
The current approach of the code mentioned by Kristof is bad in so many ways: There is a lock and within that lock there is a loop within a loop, so the complexity is exponential. These loops and comparison should be moved outside of the lock, then a new list could be prepared which contains old and new rules so within the lock a fast copy operation could be done with no need to iterate multiple times over the entire ruleset while holding a lock.
That's of course assuming that it is actually intended and necessary to copy while holding a lock.
Updated by Flole Systems over 4 years ago
To add to this: Removing the "set keepcounters" option from /etc/inc/filter.inc seems to fix it. So if someone doesn't care about the counters, just remove that line for now.
Updated by Michael Novotny over 4 years ago
Flole Systems wrote in #note-8:
To add to this: Removing the "set keepcounters" option from /etc/inc/filter.inc seems to fix it. So if someone doesn't care about the counters, just remove that line for now.
I can confirm that commenting out $rules .= "set keepcounters\n"; on line 433 of /etc/inc/filter.inc does indeed stop the high latency from occurring. According to hrping, my latency went from over 2700ms to between 50-275ms when the filter applied, then back to normal single digit latency once script was finished.
If you are running HA, it would need to be done on all firewalls as a fix in the mean time.
 Updated by Mateusz Guzik over 4 years ago
Updated by Mateusz Guzik over 4 years ago
- Assignee changed from Kristof Provost to Mateusz Guzik
I had a look at the issue with a profiler. While the loop you are mentioning is a problem to some extent, the real issue is what the loop is doing inside (md5 hashing of all rules).
%SAMP IMAGE FUNCTION CALLERS 23.6 kernel lock_delay __mtx_lock_sleep 16.6 kernel MD5Transform MD5Update:11.2 MD5Final:5.4 12.4 kernel MD5Update pf_hash_rule:9.1 pf_hash_rule_addr:3.1 9.3 kernel sched_idletd fork_exit 6.2 kernel memcpy_erms pf_hash_rule:4.0 pf_hash_rule_addr:1.5 1.7 kernel strlen pf_hash_rule 1.6 kernel rn_addmask rn_lookup 1.5 kernel rn_match rn_lookup 1.4 kernel pf_hash_rule pf_commit_rules 1.1 libc.so.7 __free SHA512_224_Update 0.8 kernel smp_rendezvous_action 0.7 kernel rn_insert rn_addroute 0.7 kernel rn_walktree pfr_ina_commit 0.6 kernel strcmp 0.6 kernel memset_erms uma_zalloc_arg 0.6 kernel cpu_idle sched_idletd 0.6 kernel MD5Final pf_commit_rules 0.5 libc.so.7 inet_ntoa
The lock_delay thing is an attempt to get any traffic.
This particular issue can be mostly solved by pre-computing the hash so that a comparison is no longer so expensive. But even then, as you noted, that's a lot of work.
Complete fix would rework the entire ruleset loading mechanism to do it in one go, as currently it is performed a series of syscalls, each of which temporarily takes the rules lock for writing.
I expect to have some patches next week.
Taking the ticket as discussed with Kristof.
Updated by Flole Systems over 4 years ago
I don't even fully understand why there's hashing going on instead of comparing directly, that doesn't really make any sense and as you noted wastes CPU time. Rewriting that compare function so it compares and returns 0 as soon as there's a mismatch, otherwise 1 would accelerate this a lot already while also eliminating the (low) risk of a hash collision.
All we really need though is a map of old/new rules though so we can iterate over the new rules and copy the old ones, right? That could get prepared outside of the lock and then within the lock that list gets iterated over and the counters get copied over. It just needs to be made sure that the ruleset is not modified in the meantime.
But maybe it's not even necessary to stop traffic passing through, there's an atomic_add function in FreeBSD so you could make the new ruleset active and then add the old count while there's already traffic passing through again. You'd just need to block the statistic retrieving until the counter adding is done so there is no chance invalid values are retrieved.
The entire freeing of the old rules can probably be kicked out of the lock aswell.
I'd really appreciate it if you find other ways to further optimize the time in the lock by looking at other parts of the code and reduce reload latency spikes even further.
Updated by Mateusz Guzik over 4 years ago
As a status update I added a red-black tree so that rules can be looked up cheaper. Pre-computed md5 hash is used as the key.
With this in place on my test box with ~3100 rules:
before: 0.81s user 8.47s system 99% cpu 9.284 total
after: 0.89s user 0.44s system 99% cpu 1.332 total
At the same time amount of work done with the lock held was reduced.
I'm going to be able to ship you a test kernel early next week. As is patches have rough edges which may end up crashing in production environment.
Updated by Flole Systems over 4 years ago
Why is there any need for hashing? You want to compare rules if I understand that correctly, there's no need to hash anything....
Also as I said the atomic add operation could be used here, that would lower the time that lock is held aswell.
Also have you compared to a case where the keepcounters-option isn't set? We're looking at a negative performance impact of that addition, so even if it got better now it might still be a lot slower than previously.
 Updated by Kris Phillips over 4 years ago
Updated by Kris Phillips over 4 years ago
Have run into this bug twice with customers, once with a standalone firewall that had 200+ interfaces and another with an HA pair with a large ruleset.
Symptoms include:
1. VGA/Serial output delays/lag in input
2. High Load Averages on one or (if applicable) both firewalls
3. webConfigurator not responding or slow
Applying the recommended workaround patch in System Patches makes this issue go away.
 Updated by Kevin Bentlage over 4 years ago
Updated by Kevin Bentlage over 4 years ago
Have the same issues on our PFSense 2.6.0 cluster (2 members) after upgrading from 2.5.2.
Firewalls have 75 interfaces and somewhere around 1500 rules loaded.
Symptoms:
1. Console delay/lag in input
2. High load spikes (caused by pfctl)
3. Temporary disconnects of the vlans / interfaces. Results in downtime on our networks.
4. OpenVPN connections are dropped / disconnected
5. WebConfigurator not responding or slow (Nginx 503 errors). After restarting the WebConfigurator and PHP-FPM services the issues are resolved (for a short period of time)
6. (re)loading the firewall rules are taking really long, on 2.6.0 this takes around 5 minutes. On 2.5.2 this took 10 - 20 seconds.
7. CARP failover is flapping between the 2 member nodes.
I've applied the workaround patch in "System Patches" and this seem to solve most of the issues. The WebConfigurator is still slow/unstable and the (re)loading the firewall rules ("Configuring firewall...") on boot is taking a few minutes.
Updated by Kris Phillips over 4 years ago
Wanted to add additional observations from situations I've seen this issue crop up:
1. pfBlockerNG causes this with large rulesets as it reloads the filter on a cron schedule
2. HA configurations with XMLRPC Sync run into this because the primary and secondary reload filters as well
Updated by Mateusz Guzik over 4 years ago
Apologies for late reply, other things got in the way.
Flole Systems wrote in #note-13:
Why is there any need for hashing? You want to compare rules if I understand that correctly, there's no need to hash anything....
Pre-hashing allows for cheaper comparison -- only the hash, not the entire rule, which is hundreds of bytes.
Also as I said the atomic add operation could be used here, that would lower the time that lock is held aswell.
Atomic operations are of no use here I'm afraid. The counter is distributed per-CPU (that is each CPU has its own). Currently the code holds the rules lock for writing in part to be able to obtain a stable snapshot without losing any actions as they happen to pass through while configuration change is taking place. As counters are specifically allocated to work this way, the real fix would simply avoid allocating another set for the new config and instead reusing them when a matching rule is found. This unfortunately requires some surgery which I elected not to do at this time.
Also have you compared to a case where the keepcounters-option isn't set? We're looking at a negative performance impact of that addition, so even if it got better now it might still be a lot slower than previously.
I did not benchmark this specifically. I managed to straight up remove some of the work previously done, so I would expect the net single-threaded reload time to be about the same despite hashing (if not slightly faster). What really matters here is that the total time the rules lock is held is reduced significantly, meaning it stalls other cores to a much smaller extent and it may be perfectly tolerable now.
If things turn out to still be too slow, I can continue the rework to make loading happen with virtually no stall for other cores. That is however time consuming to implement.
Updated by Mateusz Guzik over 4 years ago
Kevin Bentlage wrote in #note-15:
Have the same issues on our PFSense 2.6.0 cluster (2 members) after upgrading from 2.5.2.
Firewalls have 75 interfaces and somewhere around 1500 rules loaded.
Symptoms:
1. Console delay/lag in input
2. High load spikes (caused by pfctl)
3. Temporary disconnects of the vlans / interfaces. Results in downtime on our networks.
4. OpenVPN connections are dropped / disconnected
5. WebConfigurator not responding or slow (Nginx 503 errors). After restarting the WebConfigurator and PHP-FPM services the issues are resolved (for a short period of time)
6. (re)loading the firewall rules are taking really long, on 2.6.0 this takes around 5 minutes. On 2.5.2 this took 10 - 20 seconds.
7. CARP failover is flapping between the 2 member nodes.I've applied the workaround patch in "System Patches" and this seem to solve most of the issues. The WebConfigurator is still slow/unstable and the (re)loading the firewall rules ("Configuring firewall...") on boot is taking a few minutes.
Hi Kevin,
can tell me what are the hardware spec if the problematic machines? A likely fix will be available soon for testing, if you are interested.
Updated by Kevin Bentlage over 4 years ago
Mateusz Guzik wrote in #note-18:
Hi Kevin,
can tell me what are the hardware spec if the problematic machines? A likely fix will be available soon for testing, if you are interested.
2x Dell PE R620
- 2x Xeon E5-2650v2 (2.60GHz)
- 64GB RAM
- 4x 1 Gbit NIC
- 2x 10 Gbit NIC
- 4x 120GB SSD (RAID-5)
Updated by Mateusz Guzik about 4 years ago
Huh, apologies for lack of updates.
The issue is largely fixed for over 3 weeks now in the snapshots. If you can't install a snapshot, I can provide you with a patched kernel for whatever version you are running right now, just give me uname -a.
The patchset has one remaining bug which I expect to fix today, but you are not going to run into it if you don't use miniupnp.
Updated by Kevin Bentlage about 4 years ago
Mateusz Guzik wrote in #note-21:
Huh, apologies for lack of updates.
The issue is largely fixed for over 3 weeks now in the snapshots. If you can't install a snapshot, I can provide you with a patched kernel for whatever version you are running right now, just give me uname -a.
The patchset has one remaining bug which I expect to fix today, but you are not going to run into it if you don't use miniupnp.
I cannot (want to) run the snapshot version in our production environment. If you can supply the patch that would be nice.
FreeBSD fw01.xxxxx.io 12.3-STABLE FreeBSD 12.3-STABLE RELENG_2_6_0-n226742-1285d6d205f pfSense amd64 FreeBSD fw02.xxxxx.io 12.3-STABLE FreeBSD 12.3-STABLE RELENG_2_6_0-n226742-1285d6d205f pfSense amd64
Any ideas on when this patch will be released on the stable branch?
 Updated by Marcos M about 4 years ago
Updated by Marcos M about 4 years ago
Mateusz Guzik wrote in #note-21:
Huh, apologies for lack of updates.
The issue is largely fixed for over 3 weeks now in the snapshots. If you can't install a snapshot, I can provide you with a patched kernel for whatever version you are running right now, just give me uname -a.
The patchset has one remaining bug which I expect to fix today, but you are not going to run into it if you don't use miniupnp.
Does this mean the patch which removes $rules .= "set keepcounters\n"; is no longer necessary on current snapshots?
Updated by Kris Phillips about 4 years ago
Mateusz Guzik wrote in #note-21:
Huh, apologies for lack of updates.
The issue is largely fixed for over 3 weeks now in the snapshots. If you can't install a snapshot, I can provide you with a patched kernel for whatever version you are running right now, just give me uname -a.
The patchset has one remaining bug which I expect to fix today, but you are not going to run into it if you don't use miniupnp.
Mateusz,
What miniupnp issue should we be looking out for in testing and how is it reproduced? Is there another redmine for it? I'd be happy to spin up a large rule set on a 22.05 image and test.
Updated by Kris Phillips about 4 years ago
Hello,
Can we please get an update on this and what needs to be tested before release?
Updated by Steve Wheeler about 4 years ago
Ruleset load times in 22.05 look like:
[22.05-BETA][admin@5100.stevew.lan]/root: pfctl -sr | wc -l
1136
[22.05-BETA][admin@5100.stevew.lan]/root: time pfctl -f /tmp/rules.debug
0.524u 0.492s 0:01.08 93.5% 211+180k 1+0io 0pf+0w
Tested in: 22.05.b.20220523.0600
Updated by Michael Novotny about 4 years ago
Steve Wheeler wrote in #note-26:
Ruleset load times in 22.05 look like:
[...]Tested in: 22.05.b.20220523.0600
from note 1
[22.01-RELEASE][root@5100.stevew.lan]/root: pfctl -sr | wc -l
1121
[22.01-RELEASE][root@5100.stevew.lan]/root: time pfctl -f /tmp/rules.debug
0.520u 2.295s 0:02.81 100.0% 203+182k 1+0io 0pf+0w[21.05.2-RELEASE][root@5100.stevew.lan]/root: pfctl -sr | wc -l
1116
[21.05.2-RELEASE][root@5100.stevew.lan]/root: time pfctl -f /tmp/rules.debug
0.302u 0.270s 0:00.57 100.0% 202+176k 0+0io 0pf+0w
Ouch. Still nearly twice a long as version 21.05.2 but at least 4-5 times quicker than 22.01.
Updated by Marcos M about 4 years ago
Here are some additional results between current and previous versions.
====21.05====
[21.05-RELEASE][root@site-ab-router.lab.arpa]/root: pfctl -sr | wc -l
1100
[21.05-RELEASE][root@site-ab-router.lab.arpa]/root: time pfctl -f /tmp/rules.debug
0.030u 0.022s 0:00.05 100.0% 224+196k 1+0io 0pf+0w
[21.05-RELEASE][root@site-ab-router.lab.arpa]/root: time /etc/rc.filter_configure_sync
0.490u 0.189s 0:00.69 97.1% 2687+279k 2148+46io 3pf+0w
====22.05====
[22.05-BETA][root@site-ab-router.lab.arpa]/root: pfctl -sr | wc -l
1100
[22.05-BETA][root@site-ab-router.lab.arpa]/root: time pfctl -f /tmp/rules.debug
0.240u 0.155s 0:00.40 97.5% 214+183k 1+0io 0pf+0w
[22.05-BETA][root@site-ab-router.lab.arpa]/root: time /etc/rc.filter_configure_sync
0.621u 0.395s 0:01.05 96.1% 2015+250k 2172+44io 3pf+0w
On a different VM for which I only have 22.05 results, but significantly larger configuration (/tmp/rules.debug is 2527.43 KiB vs 439.36 KiB), I did notice much higher latency. Compared to 22.01 where there was packet loss, this time there's no packet loss:
[22.05-BETA][root@dut]/root: pfctl -sr | wc -l
898
[22.05-BETA][root@dut]/root: time pfctl -f /tmp/rules.debug
0.777u 0.808s 0:01.59 98.7% 211+180k 1+0io 0pf+0w
[22.05-BETA][root@site-ab-router.lab.arpa]/root: ping -i 0.1 10.0.50.1
PING 10.0.50.1 (10.0.50.1): 56 data bytes
64 bytes from 10.0.50.1: icmp_seq=0 ttl=64 time=0.345 ms
[...]
64 bytes from 10.0.50.1: icmp_seq=38 ttl=64 time=0.345 ms
^C
--- 10.0.50.1 ping statistics ---
39 packets transmitted, 39 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.188/19.600/311.000/61.209 ms
 Updated by Jim Pingle about 4 years ago
Updated by Jim Pingle about 4 years ago
- Category changed from Unknown to Rules / NAT
- Status changed from New to Resolved
- % Done changed from 0 to 100
As there is no packet loss and the impact is significantly better than the last release we can call this solved for now.
We can create a new issue to revisit the performance in the next version if further refinements are possible.
Updated by Jim Pingle about 4 years ago
- Subject changed from High latency when reloading the ruleset to High latency and packet loss during a filter reload
Updating subject for release notes.
Updated by Flole Systems about 4 years ago
There is still packet loss by the way and latency spikes up to 300ms on 22.05.... It becomes super obvious when the tinc-VPN-Bug reloads the filter every few seconds. Of course the packet loss is not there every time, the packet has to arrive at the right time to be dropped but since that bug is causing filter reloads so often chances are quite good that some packets are lost.
To sum up what happened here: A regression what introduced which was super bad, then that regression was a little improved and now it's still worse than before but it's fixed since it's an improvement since the regression was introduced. Seriously? You break something, then Iýou fix it partially but it's still broken and you just call it fixed since I improved it a little bit?
 Updated by Chris Collins over 3 years ago
Updated by Chris Collins over 3 years ago
Hi guys feedback from myself.
I had this enabled when I first updated to 2.6.0. Had noticed no issues.
But yesterday I decided to revert the patch, and then for hours since I have been trying to figure out what was causing massive latency spikes on the device, LAN and WAN both affected, eventually realised it was happening on every firewall reload then it triggered in my head it was this issue.
But the thing is my firewall ruleset isnt that big, maybe 100 rules or so in total, so if this is still only a "maybe" to put in base code, I support it been patched in base code as even with not many rules it causes latency spikes upwards of 300ms.
/tmp/rules.debug is 69KiB.
Updated by Flole Systems over 3 years ago
Yeah unfortunately this is still an issue. As I said, it's still worse than before, even though it was improved. Increased latency has been confirmed above but it was never addressed and this was just called "solved".
Updated by Mateusz Guzik over 3 years ago
Hello.
To reiterate, there are 2 distinct issues remaining.
What was patched, was one change which resulted in O(n^2) processing with pf ruleset lock held for writing, which blocks packet processing. This bit was converted into O(nlogn) which provides a marked improvement.
Here is what was not patched:
1. single-threaded execution uses a new library which replaces an ABI-sensitive interface with a key-value format, which comes at a significant cost. While it uses time on one cpu, it does not affect packet processing on any other cpus. however, if the machine is already struggling to keep up then it will indeed cause a slowdown.
2. loading a new ruleset is performed with a series of calls, several of which cause a temporary pause in packet processing and it happens in quick succession. Some groundwork was performed to make it feasible to only do one short pause, but it's not finished yet. Going all the way to never pause would require quite a bit more work and I don't know if it is feasible.
All that said, I expect to get back to this in coming weeks.